

Did you know that the word “hippopotamus” is a word of Greek origin? Hippos- comes from “horse” and -potamos means “river”. The funny thing here would be to imagine when Greeks run into this animal for the very first time. There was not a word for every single animal around the world, so they probably thought something like “what a strange horse…!!! Maybe the river has something to do with it. Got it! It will be a hippo-potamus!”
It seems that it is easier combine meanings than to make up a new word. Humans have the inherent ability to transfer knowledge between tasks, as we have already seen in the previous posts. Deep Learning was inspired by biological systems (neurons and memory) and often is inspired in human learning:

Transfer Learning
Transfer Learning might remind us to some artificial intelligence film scenes like when Neo automatically received his martial arts training during Matrix. However, if we were to compare it is more like the “wax off – wax on” scene in Karate kid. In other words, we recognise and apply relevant knowledge from previous learning experiences. Hence, transfer learning consists in training a base network and reusing some or all of this knowledge (weights) in a related but different task. Thereby, intermediary hidden layers in computer vision are able to learn general knowledge about images(edges, shapes, textures, style…)

In the previous Wild Data series we analyzed Transfer Style, where we somehow transferred the style from one image to another through the inner understanding of a pre-trained neural network. We may consider this transfer style like a kind of transfer learning, although we are going to analyze here the typical way of transfer learning.
Why Transfer Learning?
To learn a new language is expensive, but… the more languages we speak, the easier will be to learn another one. In the same way, to train the most complex models in Deep Learning is an intense task. We could start from scratch by initializing the weights with random numbers, but it’s often better use a pre-trained network weights to start with:

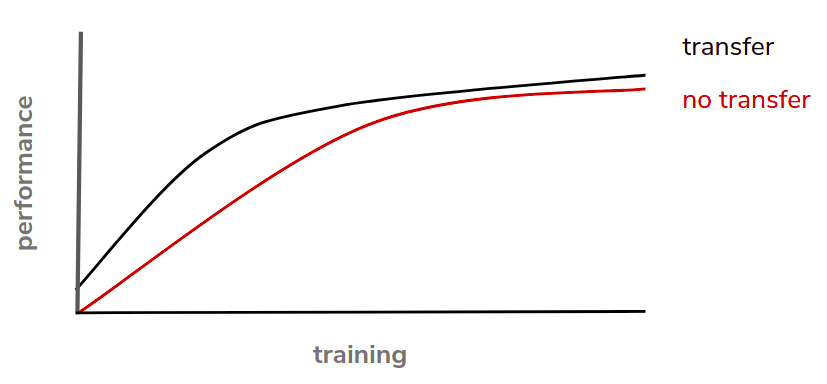
As you can see, not only will it take less time to get better results, but also less training data will be needed compared to the huge amount of data required to train the full network. In other words, just imagine that you have a smart friend who has studied very hard by understanding the whole syllabus to prepare for an exam. He has prepared very good and organized notes which he lends you and then you pass the exam by using these notes and just studying them the night before. Mmm… I think I take a shine to this guy. In the same way, you could reuse weights you have previously built, or just download them from the official website and try to load them into your own model. Also, you could use Keras, which makes your life easier by providing you some models for image classification in a very simple way (VGG19, ResNet50, InceptionV3…) Note: be aware of the input “image_size” that are given to each pre-trained model.
So, should I always use Transfer Learning?
Yes, you should use it whenever it makes sense. No kidding! Transfer learning looks pretty awesome but you have to take into account the context in which it will be used. If, for example, you need to carry out an infrared light problem, it will work horribly if we use a network that has been trained in visible spectrum. Thus, the strategy will mainly depend on the amount of data available and the similarity of this data:

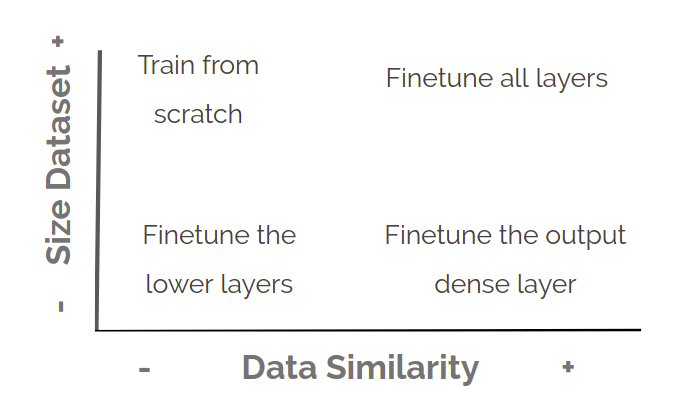
It is clear that you should have a lot more data for training the pretrained model than your new task. Besides, low level features from the pretrained model could be helpful for training the new one, and then it is necessary to remove the last Fully-Connected layer of the network, and to add instead the classifier adapted to your new task. On the other hand, fine-tuning is a destructive process that forgets previous knowledge in order to train a new one quickly or waste less time during training. You might as well freeze the weights for all or lower layers of the network and just fine-tune the layers which are not frozen.

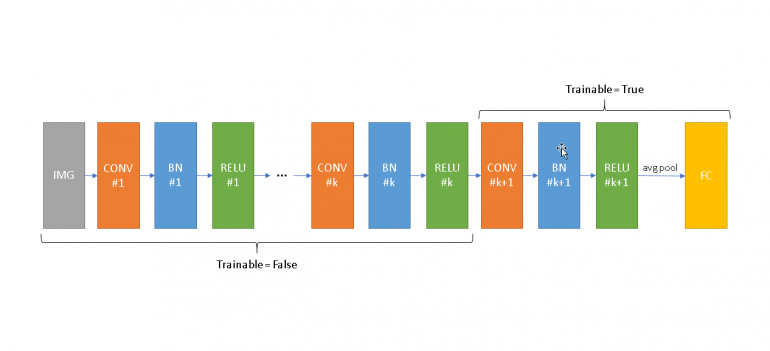
In conclusion, most of companies could benefit from shipping faster to production of Deep Learning models already trained. Computer Vision has been the field which has seen better improvements, but recent research (ELMo, ULMFiT, and the OpenAI transformer) have demonstrated that transfer learning can be used too on a wide range of Natural Language Processing tasks. It should be pointed out that other particular application of transfer learning could be simulations, because of gathering data and training a model in the real world could be expensive or just too dangerous (for instance, some situations like autonomous driving).
If you want to learn more about Deep Learning take a look at our last Data Science Meetup we organized at Campus Madrid:
– Video
– Presentation







