
This will be the last installment in the “Continuous Delivery in depth” series. After the good and the bad, here comes the ugly. Ugly because of the amount of changes required: a pull request with 308 commits was merged adding 2932 lines, whilst removing a whooping 10112. This represented about a 75% loc reduction, obviously improving the maintainability.
To go further on the topic, on 27 April 2017 you have the opportunity to join the first JAM in Madrid: confirm your assistance!
Meanwhile, you can continue with the reading…
The explained amount of changes required were (see the below images showing the increase) just for obtaining multibranch jobs.
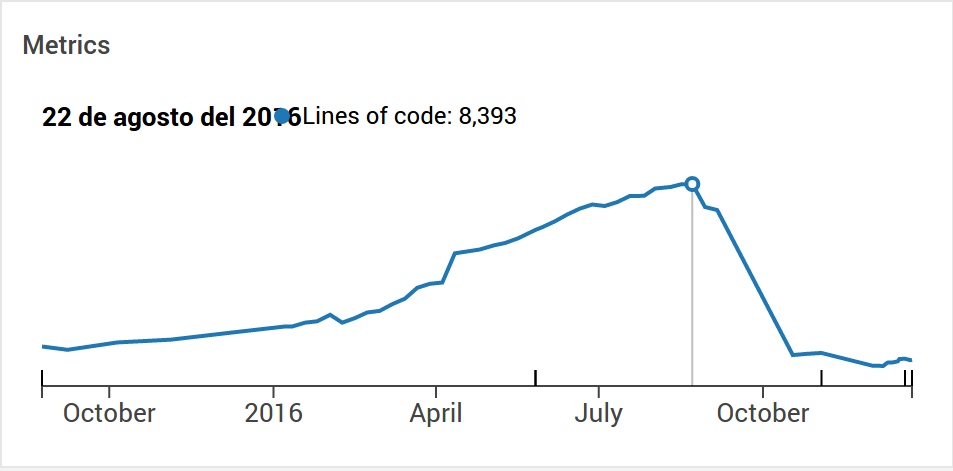
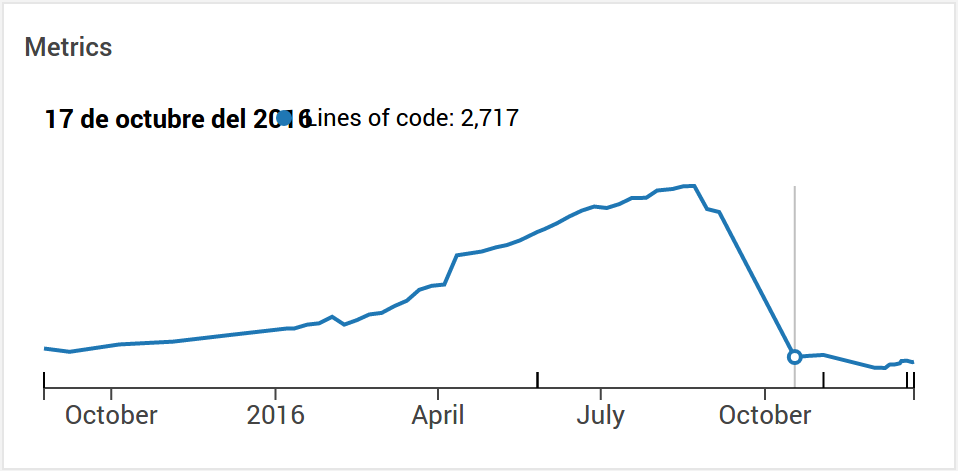
Multibranches to the rescue!
We leaped from a pretty complex environment, where each Jenkins job was responsible of handling of PRs, merge events and releases, to a split up schema. Using Jenkins’ Pipeline Multibranch Plugin, GitHub Branch Source Plugin and Bitbucket Branch Source Plugin, we have ended with an automated job creation system.
From the multi-purpose pipelines to the real multibranch library, several things have happened:
-
- Common method repository:
We had a humongous, monolithic file (+ than 3100 loc) with every method available, public and private ones (even groovy don’t give a s*it about privacy!). Finally, we have mutated to a class, containing just “private” methods.
- Common method repository:
-
- Configuration file contents:
We had a groovy class, read with the load step and shared among every piece of code. Shared Groovy Libraries usage forced us to define a default configuration map, being passed as reference to every piece of code at the library. This default configuration gets overridden by each corresponding variable defined at each Jenkinsfile, obtaining a unique configuration map for each development. This change also allowed us to ditch a .jenkins.yml file where we previously stored some of the configuration values.
- Configuration file contents:
-
- Project structure:
We had a runner, a default configuration, a common method repository and as much scripts as developments at Stratio. We have switched to classes for unit testing, a common method repository, several global functions -thanks to Pipeline Shared Groovy Libraries Plugin– and a Jenkinsfile (we fancy eat our own dogfood). Each Stratio’s development will handle each own Jenkinsfile.
- Project structure:
-
- New global variables:
These are the “public” methods previously stuck among the private ones at the old common method repository. They have been now implemented as a method call, being invoked as closures with parameters (remember the configuration map from “configuration file contents”).
- New global variables:
-
- New own Jenkisfile:
The simplest available one:
- New own Jenkisfile:
@Library('libpipelines@master') _
hose {
EMAIL = 'qa'
SLACKTEAM = 'stratioqa' // We love to be notified
DEVTIMEOUT = 15 // Don't want jobs being hung
MODULE = 'pipelines'
REPOSITORY = 'github.com/continuous-delivery' // Needed for release jobs, also using this Jenkinsfile
DEV = { config ->
doUT(conf: config) // We run our small set of unit tests
parallel(DOC: {
doDoc(conf: config) // Build and publish groovydocs
}, QC: {
doStaticAnalysis(conf: config) // Trying to keep code quality under control
}, failFast: config.FAILFAST)
}
}
- Self hosted developments Jenkinsfiles:
Lookig at Crossdata as an example, we can see a main closure -named “hose”, since “pipeline” is an already used name (damn pipeline model definition plugin!)- containing each wanna-be overwritten configuration variable plus several (one in this case) inner closures: DEV. This closure will define the actions invoked from the available global variable ones. Alternatively, there could be an AT or PERFT defining actions for acceptance tests or performance test jobs. In Crossdata’s case, each acceptance test is being run at each PR open, synced or merged.Altough Shared Groovy Libraries Plugin offers a way to document each public variable, we have opted to build our own groovydocs, being uploaded to Stratio’s s3 bucket. Shamefully, those groovydocs contain every implicit groovy method, but digging we can find the real deal doCompile class.
Further simplifications
* Jenkins won’t be responsible for squashing PRs as github does a better job
* No code will be responsible for setting the PR statuses, since other Jenkins’ plugins do a better job
* Every configuration option is overwritable. Previously only some of them were.
* PRs and merge events share actions, just some of the steps mutate. PRs docker images are being pushed to a different docker registry or packages built are not being deployed.
* Releases also share actions with PRs and merge events, again with omitted actions. We used to compile and package, when maven projects could led to longer run times due spurious recompiling.
* Pipeline library gets a proper versioning, being the same as other Stratio developments. Each Jenkinsfile can be modified to choose the version (branch) that should be used.
As with great power comes great responsibility, we are forced to manually create jobs for our acceptance tests and release process.
PS: Kudos to Antonio Muñiz (@amunizmartin), this work’s advocate, a Software Engineer @CloudBees (the main company after the Jenkins effort).


