
During last week some controversy arose from a Deep Learning critical Whitepaper. Although many of the main points can be attributed to Supervised Learning in general, on the other hand, some useful self-critical ideas can be extracted, specially when the Deep Learning world is becoming mainstream.
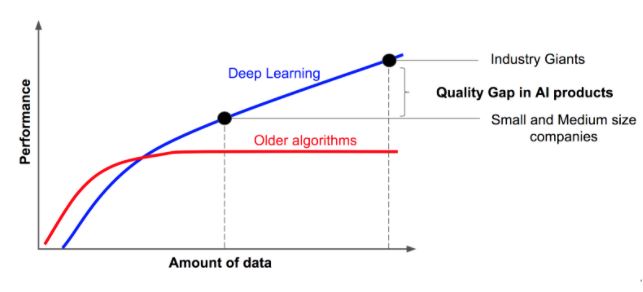
Deep learning is a fast growing subset of machine learning. The key to the success of these methods lies in the rich representations these models build, which are generated after an exhaustive and computationally expensive learning process. Thus, it is already clear to organizations that deep learning is starting to become essential to specialized areas of business. Nonetheless, it is not the panacea and we should not try to use it for every single problem.
Many yet-to-be practitioners expect deep learning to give them a mythical performance boost just because it worked in other fields. Sometimes initial conditions are not the best for deep learning algorithms and before seeing everything as a nail, we could perhaps think about using something else besides a hammer. So, it might be interesting to have a look at some general advice on when deep learning is probably not going to be the best choice before you immerse yourself in a project of this nature.
What should not be done?
- DO NOT work just with a bunch of small sample sizes. Historically neural networks architectures were discarded in part due to lack of data. These architectures are immensely data-hungry to improve precision. In spite of that, it is true that there are techniques, like transfer-learning, with which you can see some benefit from deep learning by using small datasets, although it is very likely that you will probably end up needing simply more data, or different data, when the network does not provide the accuracy you expected.
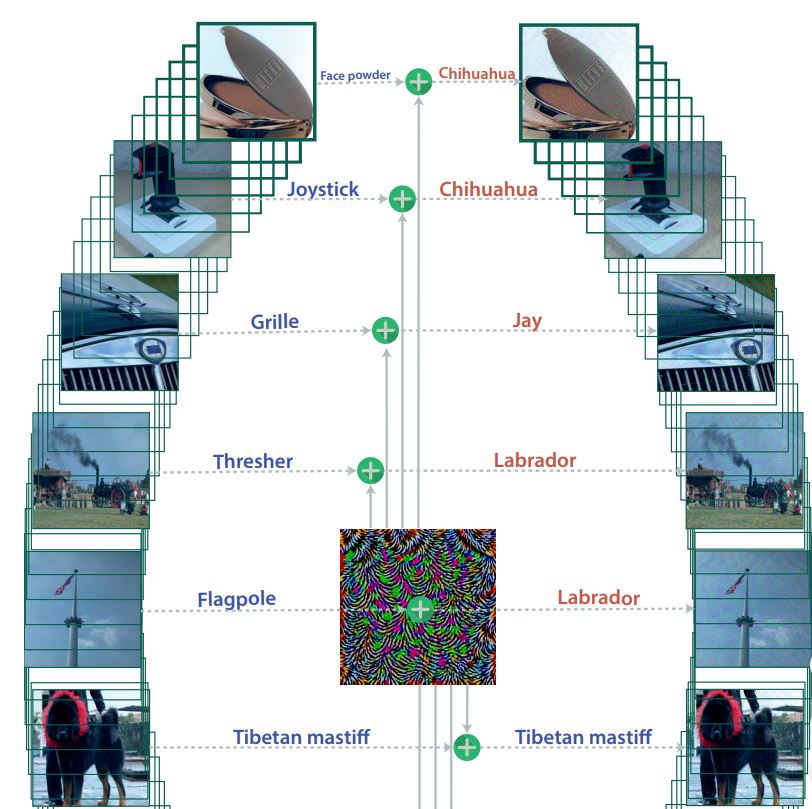
- DO NOT use supervised learning algorithms on weakly labeled data. Due to its complex nature, deep learning algorithms are able to dig deep into data and find relationships among the data that sometimes are far from trivial. On the other hand, in the case of wrongly labeled data, it is possible for the algorithms to find false relationships, which can lead to a very poor outcome.

-
-
- DO NOT train in a non-balanced label distribution: real world is messy and datasets are mostly non-balanced. That means for supervised classification problems there are usually equally as many samples per class.
-

-
-
-
- DO NOT think it is magically set up: there are many friendly deep learning environments that allow an easy-usage of model fitting, with some default parameters that reflect “most common practices”. Even so, you still need to make sure the parameters you have selected are good for your problem and debug. Knowing how to optimize your parameters and how to partition data to use them effectively is crucial getting good convergence in a reasonable amount of time.
-
- DO NOT confuse deep learning with an artificial brain simulator: real neurons behave in a totally different way and in spite of showing a human-level or even superhuman performance on the specific tasks, experiencing a single universal adversarial perturbation could cause a network to fail on almost all images, and this perturbation is so subtle that it is invisible to any human being.
-
-
-
-
-
- For this reason, even though it is a pain, on some occasions you might spend some time training on totally black or random noise images!
-
- DO NOT discard alternative methods. You might be pleasantly surprised that an easier one (like linear models or decision trees) is really all you needed. Hence, try to spend 1/3 of your time researching and 2/3 doing. After all, there is a more than 50 year history of flexible and maturity models in machine learning and statistics.
-
- DO NOT try to understand the model in one shot: every model is interpretable, but sometimes more complex techniques are required than the model itself. Thereby, some industries, such as investment, medical, insurance or military decision are not allowed to be used at a high level because decisions made cannot be clearly explained. In addition, another downside to black-box algorithms, low level insights are hardly ever found without easy interpretability possibilities. This is probably not the choice in case you are looking for a self-exploratory solution.
-
-

-
-
- And for sure… DO NOT attempt to find pattern correlations that do not exist: If no human can predict something, it is very likely deep learning can not either. Recently, there has been training to learn criminality features on faces.
-
In conclusion, training deep nets carries a big cost in both computational and debugging time. At the same time, it is clear that deep learning is not a “silver bullet”, its usage depends on the data and the nature of the problem. As it is known one of the virtues it is best known for is to generate a whole new bunch of problem-related features, but we cannot think of it as an automatization for feature engineering, as the net parametrization will probably depend on the available features. Data has to also to be taken care of, in terms of dimensions and variety. As its complexity grows, it needs to be fed more and more to be feeded gets bigger and bigger. We cannot trust a little to be able to train many parameters.
Moreover, remember the network builds its own representation of the data in a (probably) higher dimensional space, which is indeed an unsupervised idea. When the whole thing is supervised we are forcing the system to translate its representation to something we consider an absolute truth: the labels. If these labels tend to be wrong, perhaps an unsupervised approach could fit better into that self-representation.
And finally a tip, be aware! There are many factors at play here, but deep learning will merely learn the bias. Skynet can wait.


