
In the previous post about Apache Ignite, we learnt how to set up and create either a simple cache or a sql cache, and share the cached data between different nodes. In this post, we will dig a little deeper. We will see what to do if our app crashes because the cached data has disappeared. How could Ignite help us avoid this problem?
Let’s suppose that we are working on a real-time IoT application, designed to receive events from devices such as temperature devices, GPS, or events from raspberry sensors. We assume that an event has organized data that is static like an event ID, metadata, lat-long coordinates for geospatial queries (shortest route maybe). A backoffice application also exists through which the users can create the devices metadata based on an unique ID (the same as the received events), like the imei, or gpio, etc.
Sensors can send events every minute or even less, in the case of the GPS. We often come up against the requirement of enriching the dynamic data with the static data, with the advantage that the devices are usually waiting for the ack message. How can Apache Ignite help us with this situation? For example, with static data and dynamic data in multiple microservices? Besides using the cache benefits of Ignite as we have seen in the previous post (replication, repartition, queries), does Ignite have persistence with just the cached data? Let’s take a deeper look at this point.
Persistence
There are a variety of databases that are suitable for persist data, but how many in-memory platforms provide cache and storage without boilerplate code?
Here is a simple example to show how it works (we will use Postgres as database, and Scala).
Let’s get started! Add the following dependencies in your build.sbt file:
libraryDependencies ++= Seq(
"org.apache.ignite" % "ignite-core" % "2.6.0",
"org.postgresql" % "postgresql" % "42.2.4"
)Then configure the Ignite cache as usual, adding the persistence properties
val NativePersistence = "device_native"where data will be stored
val PersistencePath = "/tmp/ignite"where write-ahead log will be stored
val WalPath = "/tmp/wal"
val config = new IgniteConfiguration()The purpose of the WAL is to provide a recovery mechanism for scenarios where a single node or the whole cluster shuts down
In this section, we configure the cache backup nodes, cache mode, and expiration policy for the data. For an overview, check Partition and Replication on the previous post.
val cacheCfg = new CacheConfiguration(NativePersistence)
cacheCfg.setBackups(1)
cacheCfg.setCacheMode(CacheMode.REPLICATED)
cacheCfg.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC)
cacheCfg.setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(new javax.cache.expiry.Duration(TimeUnit.SECONDS, 30)))Here, we tell Ignite, that we want to persist the cache enabling the persistence:
val storageCfg = new DataStorageConfiguration()
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true)
storageCfg.setStoragePath(PersistencePath)
storageCfg.setWalPath(WalPath)
storageCfg.setWalArchivePath(WalPath)
config.setDataStorageConfiguration(storageCfg)
config.setCacheConfiguration(cacheCfg)
val ignition = Ignition.start(config)
ignition.cluster().active(true)
val cache = ignition.getOrCreateCache[Int, Device](NativePersistence)
def random(min: Int, max: Int): Double = {
val r = new Random
min + (max - min) * r.nextDouble
}
for (i <- 1 to 100) {
cache.put(i, Device(i.toString, s"metadata $i", random(-90, 90), random(-180, 180)))
}And that’s all! Let’s run the app to show how it works:
[18:19:14] Data Regions Configured:
[18:19:14] ^-- default [initSize=256.0 MiB, maxSize=1.6 GiB, persistenceEnabled=true]And navigating to /tmp, you will see /tmp/ignite and /tmp/wal directories. To be sure that it works, just start another instance of the app changing this line
cache.put(i, Device(i.toString, s"metadata $i", random(-90, 90), random(-180, 180)))with this one:
println(s"Get device ${cache.get(i)}")So that now the output looks like this:
[18:54:25] ^-- default [initSize=256.0 MiB, maxSize=1.6 GiB, persistenceEnabled=true]
Get device Device[id = 1 - metadata = metadata 1 - lat = -77.53427731362423 - lon = 29.076159947913908}
Get device Device[id = 2 - metadata = metadata 2 - lat = -35.7678515281638 - lon = -13.232386332299711}
Get device Device[id = 3 - metadata = metadata 3 - lat = 11.884412857887412 - lon = 95.16134531018974}Wait until the configured expiry policy time ends and try again to see the results.
Baseline Topology
If Ignite persistence is enabled, Ignite will enforce the baseline topology concept which represents a set of server nodes in the cluster that will persist data on the disk. Usually, when the cluster is started for the first time with Ignite persistence on, the cluster will be considered inactive thus disallowing any CRUD operations. To enable the cluster, you will need to:
ignition.cluster().active(true)Expiry Policies
- In-Memory Mode (data is stored solely in RAM): expired entries are purged from RAM completely.
- Memory + Ignite persistence: expired entries are removed from memory and disk tiers.
- Memory + 3rd party persistence: expired entries are just removed from the memory tier (Ignite) and the 3rd party persistence (RDBMS, NoSQL, and other databases) is kept intact.
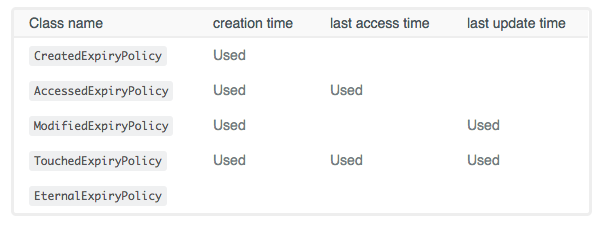
Note: By default, Ignite nodes consume up to 20% of the RAM available locally
Great! We have our persistence data on a specific path, in each node, so if a device sends an event we will enrich the message with static metadata, but…
As I mentioned above, the user can persist the devices metadata in a database. If this is the case, then our native persistence has been “pre loaded” as a database, and for each update, the application will update the database and refresh the associated value in the cache.
If the cache always depends on a database, is there any possibility to associate the database actions to the cache? Perhaps. Does Ignite have a way to put/load data into/from the cache through a database? (Reminder: Postgres is the database).
3rd Party Persistence
Note: Postgres > 9.x is required
import javax.cache.configuration.FactoryBuilder
val JdbcPersistence = "device_ignite_table"
val cacheCfg = new CacheConfiguration[String, Device](JdbcPersistence)
cacheCfg.setBackups(1)
cacheCfg.setCacheMode(CacheMode.REPLICATED)
cacheCfg.setCacheStoreFactory(FactoryBuilder.factoryOf(classOf[CacheJdbcStore]))
cacheCfg.setReadThrough(true)
cacheCfg.setWriteThrough(true)
config.setCacheConfiguration(cacheCfg)
val ignition = Ignition.start(config)
val jdbcCache = ignition.getOrCreateCache[String, Device](JdbcPersistence)CacheStoreFactory is our 3rd party persistence layer where we can manage to access/read data from the database to/from Ignite.
class CacheJdbcStore extends CacheStoreAdapter[String, Device] ...If you want to define your cache store adapter, you just have to extend from CacheStoreAdapter[K,V] class, which provides implementations for commons methods, such as:
- Load all
- Write all
- Delete all
Ignite provides
org.apache.ignite.cache.store.CacheStoreinterface which extends bothCacheLoaderandCacheWrite
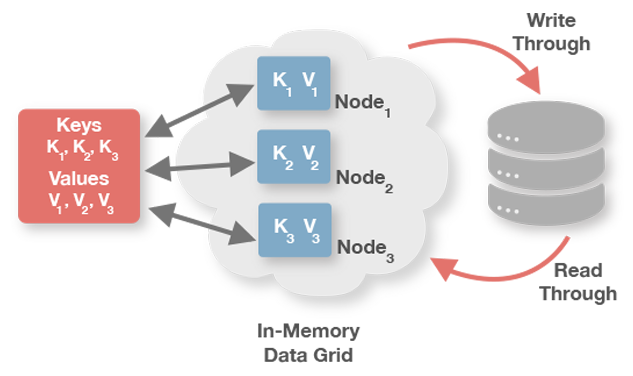
In our example, we will use mostly two of these methods: write and load.
The write method, related to cacheCfg.setWriteThrough(true). Setting it as true, means putting a value into the cache but, under the hood, it is called the write method. If it is set to false, it’s never called write method.
override def write(entry: Cache.Entry[_ <: String, _ <: Device]): Unit = Try {
// Must be an UPSERT
val ps = connection.prepareStatement("INSERT INTO device_ignite_table (id,metadata,lat,lon) VALUES (?,?,?,?)")
ps.setString(1, entry.getKey)
ps.setString(2, entry.getValue.metadata)
ps.setDouble(3, entry.getValue.lat)
ps.setDouble(4, entry.getValue.lon)
ps.executeUpdate()
} match {
case Success(_) = > println(s"Value put in table")
case Failure(f) = > println(s"Insert error $f")
}The same with read, cacheCfg.setReadThrough(true), with true value, if the values are not in cache then it will look for it in the database:
override def load(key: String): Device = {
println(s"load key $key")
val ps = connection.prepareStatement(s"SELECT * FROM device_ignite_table where id = '$key'")
val rs = ps.executeQuery()
if (rs.next())
rsToDevice(rs)
else
null
}In both cases, table name is the same as cache name
If we put some data in ‘jdbcCache’
for (i <- 1 to 10) {
jdbcCache.put(i.toString, Device(i.toString, s"metadata $i", random(-90, 90), random(-180, 180)))
}With this approach, our cache can always be updated! Depending on the case, reading or writing from the database is configurable. Besides these methods, cacheStore provides, delete and loadCache. Imagine, you can use postgres to save your app data, and maybe have a read only cache for our dashboard view, like in the example. Or even better: a write-only cache where you can put the data in cache+postgres and read it from the read-only cache.
Bonus track : CacheStoreAdapter using Slick. > Slick is a Functional Relational Mapping (FRM) library that makes it easy to work with related databases
I left the load method subject to free Future[_] interpretation 😉
Conclusion
Ignite provides us with this powerful tool to be able to maintain our data in memory or in memory+native or in memory+nosql or in memory+jdbc. It is very flexible and can be adapted to our architectures. Is is possible to use this in a CQRS model?


