")
This two-article series explains how to design and implement a hybrid recommender system that works just like the ones used by Amazon or Ebay.
Introduction
Let’s start with a short definition from Wikipedia:
Recommender systems or recommendation systems (sometimes replacing “system” with a synonym such as platform or engine) are a subclass of information filtering system that seek to predict the ‘rating’ or ‘preference’ that a user would give to an item.
The following diagram is a basic illustration:
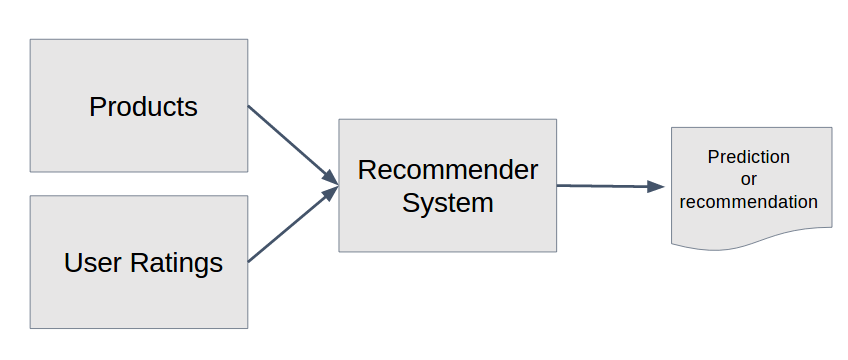
A recommender system analyses input data which contains information on different products and their user ratings. After reading and processing the data, the system creates a model that can be used to predict ratings for a particular product or user.
Approaches
In the recommender system world, there are three types of approaches to filter products:
- Collaborative filtering: this approach is based on collecting and analysing a large amount of information on users’ behaviours, activities or preferences and predicting what they like based on their similarity to other users.
- Content-based filtering: this approach is based on descriptions of user-preferences and items they have looked at or purchased in the past.
- Hybrid recommender systems: The hybrid approach combines collaborative filtering and content-based filtering.
In this article, we will use all three approaches.
Architecture
We have selected the Stratio Platform as the base-solution because it eases the task of developing applications based on Spark and many other Big Data solutions.
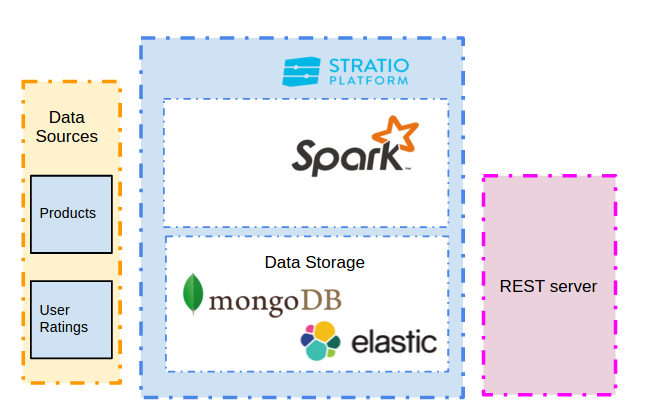
Our recommender system is divided into three main modules:
- Dataset Loader: this submodule will download the dataset from the Internet, process and store it in our two main data stores (MongoDB and ElasticSearch).
- Recommender Trainer: all the ratings stored in the DB by the previous module will be used to create a Collaborative Filtering model and pre-calculate recommendations for all users and products which will then in turn be stored in MongoDB.
- Recommender Server: using a small REST server we will send recommendation queries to MongoDB and ElasticSearch.
Dependencies
This is the list of libraries used by this system:
org.scala-lang:scala-library:2.10.6 ch.qos.logback:logback-classic:1.1.7 org.apache.spark:spark-core_2.10:1.6.1 org.apache.spark:spark-sql_2.10:1.6.1 org.apache.spark:spark-mllib_2.10:1.6.1 org.scalanlp:jblas:1.2.1 org.mongodb:casbah-core_2.10:2.8.0 com.stratio.datasource:spark-mongodb_2.10:0.11.1 org.elasticsearch:elasticsearch-hadoop:2.3.1 org.elasticsearch:elasticsearch:2.3.1 com.github.scopt:scopt_2.10:3.4.0 commons-io:commons-io:2.5 org.apache.commons:commons-compress:1.11 io.spray:spray-json_2.10:1.3.2 io.spray:spray-client_2.10:1.3.2 io.spray:spray-routing_2.10:1.3.2 io.spray:spray-can_2.10:1.3.2 io.spray:spray-caching_2.10:1.3.2 com.typesafe.akka:akka-actor_2.10:2.3.9
Dataset Loader
This submodule is responsible for downloading, reading, transforming and saving the dataset into our two data stores (MongoDB and ElasticSearch).
Here is a brief description of the dataset:
This data set contains Amazon product reviews under six categories: camera, mobile phone, TV, laptop, tablet and video surveillance systems.
Each product contains the attributes of: product ID (unique), name, product features, listing price and image URL.
Each review contains the attributes of: review ID (unique), author, title, content, overall rating, date.
Once we have downloaded the dataset to the disk, we have to read the JSON files using Spark SQL which is a very simple task:
val products = sqlContext.read.json("DATASET_DIR/*/*.json")
It is then necessary to organise all the rows of our Product/Review model:
case class Product(productId: String, name: String, val price: String, features: String, imgUrl: String)
case class Review(reviewId: String, userId: String, productId: String, val title: String, overall: Option[Double], content: String, date: java.sql.Timestamp)
def mapPartitions(rows: Iterator[Row]): Iterator[(model.Product, Option[List[Review]])] = {
val df = new SimpleDateFormat("MMMM dd, yyyy", Locale.US)
rows.flatMap { row =>
if (row.fieldIndex("ProductInfo") == -1 || row.getAs[Row]("ProductInfo").fieldIndex("ProductID") == -1 || row.getAs[Row]("ProductInfo").getAs[String]("ProductID") == null) {
None
}
else {
val productRow = row.getAs[Row]("ProductInfo")
val product = new model.Product(productRow.getAs[String]("ProductID"), productRow.getAs[String]("Name"), productRow.getAs[String]("Price"), productRow.getAs[String]("Features"), productRow.getAs[String]("ImgURL"))
val reviews = row.fieldIndex("Reviews") match {
case i if i > -1 =>
Option(row(i).asInstanceOf[mutable.WrappedArray[Row]].map { reviewRow =>
val date: java.sql.Timestamp = reviewRow.getAs[String]("Date") match {
case s: String => new java.sql.Timestamp(df.parse(s).getTime)
case null => null
}
val overall: Option[Double] = reviewRow.getAs[String]("Overall") match {
case "None" => None
case s: String => Option(s.toDouble)
}
new Review(reviewRow.getAs[String]("ReviewID"), reviewRow.getAs[String]("Author"), product.productId, reviewRow.getAs[String]("Title"), overall, reviewRow.getAs[String]("Content"), date)
}.toList)
case -1 => None
}
Option((product, reviews))
}
}
}
val productReviewsRDD = products.mapPartitions(mapPartitions).cache()
And to save the Product/Review tuples in the MongoDB:
val productConfig = ...
val reviewsConfig = ...
val mongoClient = ...
//Save the Products and Reviews using Stratio Spark-Mongodb connector
productReviewsRDD.map { case (product, reviews) => product }.toDF().distinct()
.saveToMongodb(productConfig.build)
productReviewsRDD.flatMap { case (product, reviews) => reviews.getOrElse(List[Review]()) }.toDF().distinct()
.saveToMongodb(reviewsConfig.build)
Finally, all the Products should be saved in ElasticSearch:
def storeDataInES(productReviewsRDD: RDD[model.Product])(implicit _conf: SparkConf, esConf: ESConfig): Unit = {
val options = Map("es.nodes" -> esConf.httpHosts, "es.http.timeout" -> "100m", "es.mapping.id" -> "productId")
val indexName = esConf.index
val typeName = "%s/%s".format(indexName, PRODUCTS_INDEX_NAME)
val esClient = ...
//Delete previous data
if(esClient.admin().indices().exists(new IndicesExistsRequest(indexName)).actionGet().isExists){
esClient.admin().indices().delete(new DeleteIndexRequest(indexName)).actionGet()
}
import org.elasticsearch.spark.sql._
import sqlContext.implicits._
//Save the Products using Elasticsearch-Spark connector
productReviewsRDD.toDF().distinct().saveToEs(typeName, options)
}
storeDataInES(productReviewsRDD.map { case (product, reviews) => product })
Conclusions
The first part of this series gives an overview of what a recommender system is, what its main parts are and some basic algorithms which are frequently used in these kinds of systems. We have also implemented some functions using Spark SQL to read JSON files and to organise the data in MongoDB and ElasticSearch using Spark connectors.
We have not yet coded anything related to recommendation algorithms as this will be covered in the second part of the series along with:
- Generating our Collaborative Filtering model.
- Pre-calculating product / user recommendations.
- Launching a small REST server to interact with the recommender.
- Querying the data store to retrieve content-based recommendations.
- Mixing the different types of recommendations to create a hybrid recommender.
Coming soon.


