
This post is about an exciting journey that starts with a problem and ends with a solution. One of the top banks in Europe came to us with a request: they needed a better profiling system.
We came up with a methodology for clustering nodes in a graph database according to concrete parameters.
We started by developing a Proof of Concept (POC) to test an approximation of the bank’s profiling data, using the following technologies:
- Java / Scala, as Programming languages.
- Apache Spark, to handle the given Data Sets.
- Neo4j, as graph database.
The POC began as a 2-month long project in which we rapidly discovered a powerful solution to the bank’s needs.
We decided to use Neo4j, along with Cypher, Neo4j’s query language, because relationships are a core aspect of their data model. Their graph databases can manage highly connected data and complex queries. We were then able to make node clusters thanks to GraphX, an Apache Spark API for running graph and graph-parallel compute operations on data.
Along the way, we decided to challenge another of the more well-known issues faced by banks: Detecting data redundancy in a massive database. Our client needed a function that could help them detect nodes that already had the same set of nodes (or a way to get an equality measure between them) and the possibility to create more complex queries to test their database through this information. For example, taking all the departments in a company and detecting which of them has exactly the same related users.
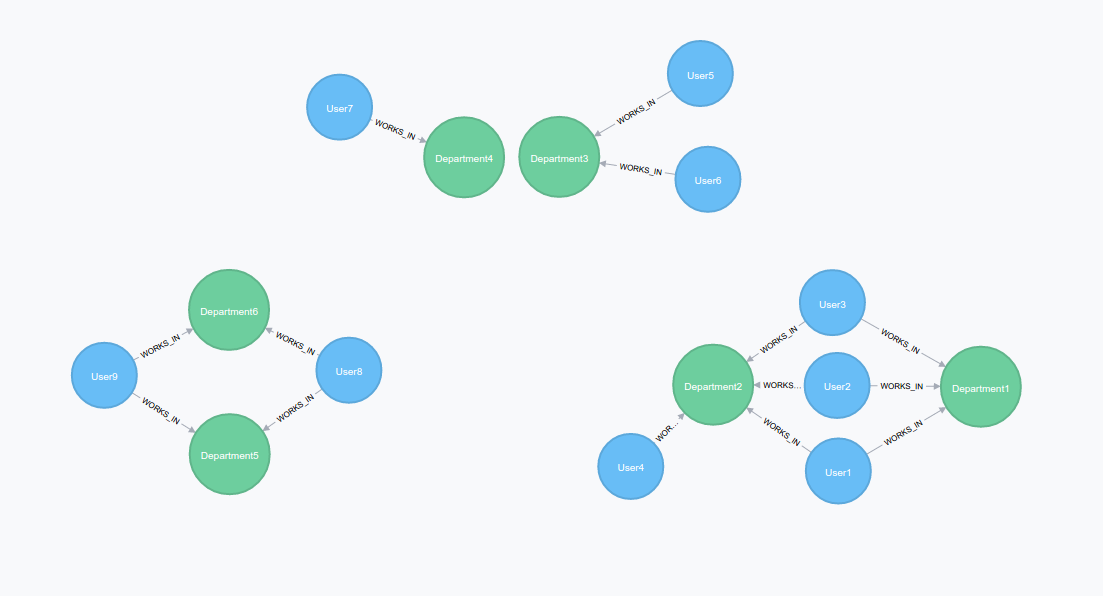
The above image shows all the possible situations that we can face in a graph database. Departments with exactly the same shared users, department that share part of their users and finally departments which manage totally different groups of user. How can we measure the difference between sets of users to detect redundant departments?
With this in mind, we can move on to our fancy solution!
Solution
The first step was the research of a math solution to get a type of measure which could help us with the set differentiation. After a couple of hours, we came across our our new best friend Paul Jaccard, who created a Similarity coefficient with the following formula.
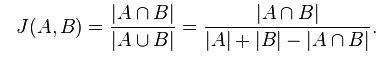
This method allowed us to detect departments with exactly the same users → J(A,B) = 0 or with totally different sets → J(A,B) = 1. Using this method, we developed a solution with Spark to compare all nodes.
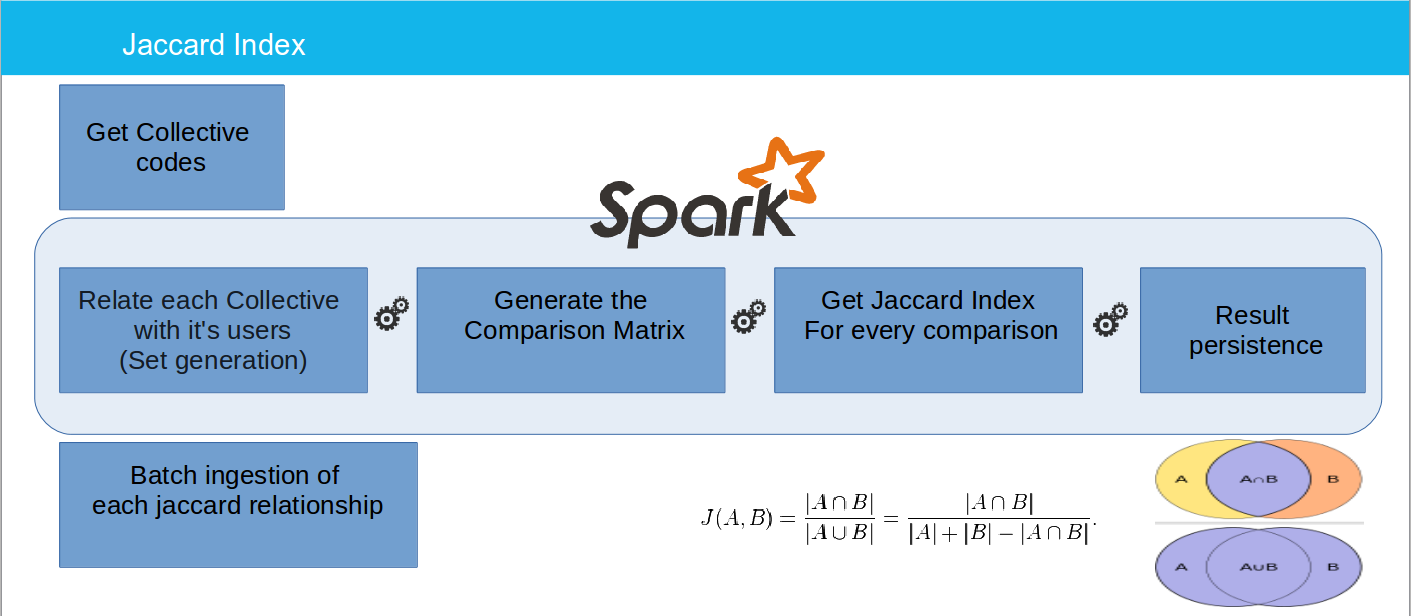
As you can see in the above image, at the end of the process we obtain a RDD with the Jaccard Index between every department. This content is then uploaded to Neo4j through a batch process. During the ingestion, we create a relationship between every department node. Each of these relationships is based on the famous Jaccard index.
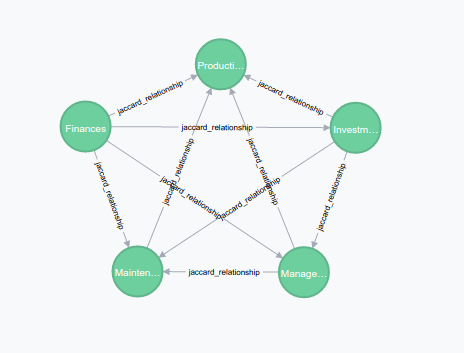
Here we can see a cluster of department nodes, with their relationship “jaccard_relationship”. As we already know, the relationship keeps the Jaccard value.
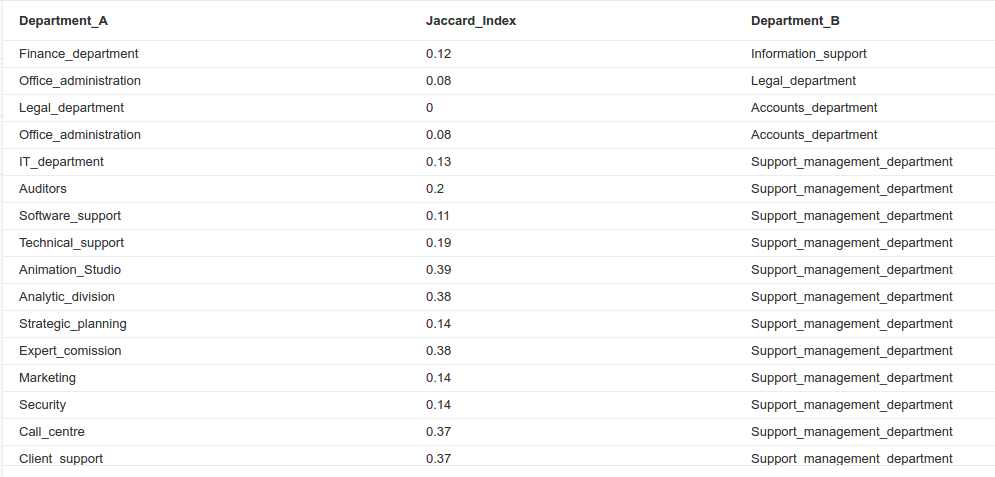
In the above example, we have set a query to show a table of related departments that don’t have exactly the same set of users. The closer to 1, the more different the sets.
This is how we solved the first problem of relating every department and finding a way to check them efficiently through Cypher queries.
The other problem was node clustering through the Jaccard Index. This is where GraphX came into the picture. Inside this API, we can find the method “Connected Components” which does exactly what we needed: relate a set of nodes through concrete parameters, for this use case it will be the jaccard iindex.
Take a look at the Jaccard + GraphX solution applied to our Neo4J database:

Every cluster of nodes is given an identifier (which is the code of the smaller node in the set) to enable us to work with it easily.
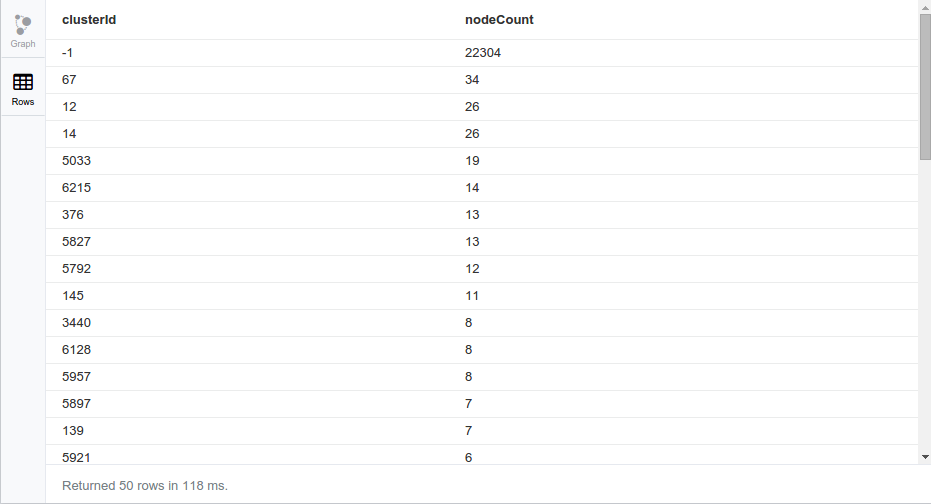
In the above query, we can see a relation of Jaccard clusters and the number of nodes inside each one. Now, let’s check the content of one of the smaller clusters…
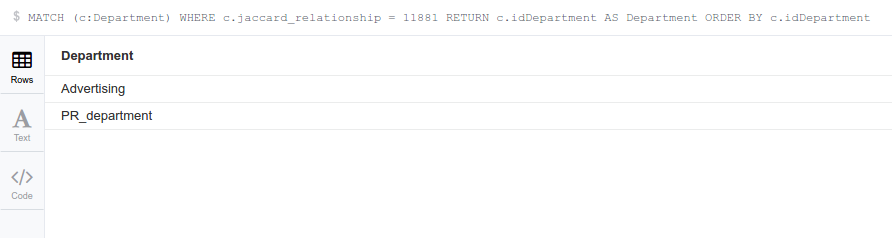
With a simple query, we are able to know all the departments inside the cluster. Now let’s check if all the departments share the same set of users:
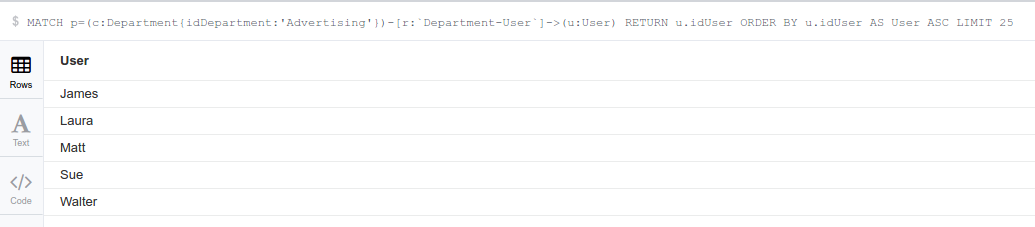

As we can see, the departments both share exactly the same users.
Main benefits of a graph database clustering solution
We have developed a generic solution that can be applied to any node inside a graph database. This enables us to create different clusters joined by the characteristics of our choice. It is a powerful way to make online queries to a graph database, which is integrated with Spark and GraphX.
In a short period of time, we are able to create different samples of the same graph with different identities or logic.
For example, if we applied the method to a film recommendation system, we could get different clusters divided by users who love the same films, film genres in a concrete period of time or the most profitable films depending on the viewer age. Just think of the possibilities and benefits of this solution when applied to even more complex projects!
To sum up, we have added a new layer to our client’s existing profiling system.
Next steps in profiling and segmentation
This solution may help solve even more complex profiling issues and can be further improved:
- By applying it to other projects with profiling or segmentation requirements.
- By comparing it to other segmentation algorithms like K-means or KKN.
- By applying new GraphX functionalities to our solution.
POC Conclusions
This has been a great experience! Thanks to all the incredible technologies and the fact that it is really easy to check results through Neo4J, we have been able to create a powerful solution for our client with the possibility of easily adding more useful functionalities to it.
The best part of this journey was seeing our client’s reaction to the result. They were both amazed and terrified by the huge amount of redundant data in their system.


