
This post aims to show how to build an on-premise Mesos architecture to handle a disaster scenario when an entire Data Center is not available, covering also some framework strategies for zero data loss.
The main tool we used to reach this goal is Project Calico, which provides a BGP-based SDN with centralized configuration and can easily peer with almost any enterprise router.
Mesos Multi Data Center Overview
Mesos not only offers a powerful solution for running containers, microservices and Big Data systems, but also provides mechanisms to help us mitigate different failure scenarios such as Master/Agent loss, Master partitioned away from the quorum, network connectivity issues, etc.
But, from the different disasters from which we want to protect our data, the scenarios involving the loss of an entire Data Center are perhaps the most difficult to handle, and those are not covered by Mesos with an SDN out-of-the-box.
In this post, I’ll show how to deploy one Mesos cluster in two Data Centers, focusing on the networking layer and mentioning some frameworks/tasks strategies.
Both, disaster recovery and business continuity plans, must contemplate a Data Center loss scenario to ensure our services will keep running and we won’t lose our precious data in case a huge catastrophe strikes.
Mesos Architecture
As you might have guessed, the main challenge for this deployment is to deal with the limitations of the physical world, mainly measured in the form of latency and bandwidth. Thus, the scenario presented for this post is based on an on-premise environment deployed in two different Data Centers, where we can have certain control of those limitations.
As a good exercise (unfortunately, beyond the scope of this post), please consider the complexity when deploying this same architecture in cloud environments, where the resources (specially the network) are managed by the provider and shared among other customers.
Since it is not very common to have an environment like the one needed to test this architecture, I don’t want to miss the opportunity to mention GNS3, a great open source tool, without which our work would have been much more difficult. As stated in their website, “used by hundreds of thousands of network engineers worldwide to emulate, configure, test and troubleshoot virtual and real networks”.
One of the difficulties for this solution is to avoid every SPOF in all the involved clusters. Unfortunately, with two Data Centers we cannot keep the service running in case the Data Center with the greater number of nodes goes down (there will be no quorum).
For that reason, we’ve decided to have an active-active deployment (for frameworks and tasks) with a main and a secondary Data Center, the first one will have the majority of nodes for all the clusters, leaving the minority in the secondary one. This means that we can handle losing the secondary Data Center without taking any action, but if the main Data Center goes down, we will need to resize the clusters for them to achieve quorum (we’ll see how later on).
It is worth mentioning that we wouldn’t have this problem with a third Data Center as a tie-breaker, but I’ll leave that architecture for another post.
Failover/Failback
To understand how the failover works in this architecture, please take the following situations:
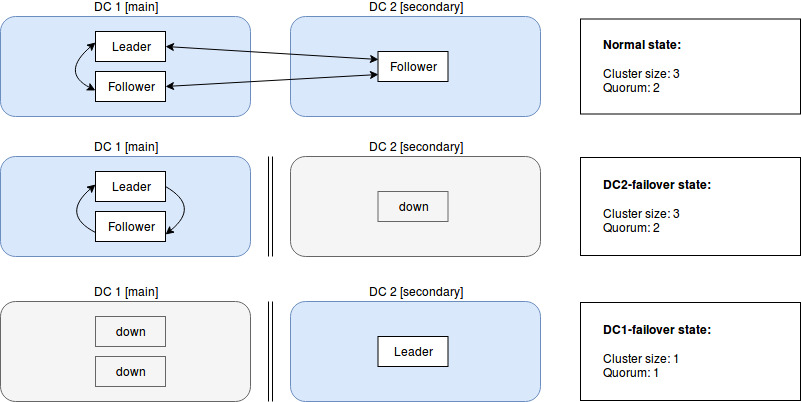
In the first one, we can see the normal state of a cluster, with the leader in the main Data Center (it can be any of the three nodes). The size of the cluster is 3 and, as usual, we need at least 2 to reach quorum.
When the secondary Data Center goes down, no action is needed. The cluster can handle this because the main Data Center can still reach quorum.
The problem arises when the main Data Center goes down, which forces us to change the size of the cluster to 1 or else the remaining node will not respond (split-brain protection), thus having an undesirable state (without HA) for a moment.
After we’ve successfully activated the failover mechanism, all our services are running in the secondary Data Center with only one node for each cluster. Here we have two choices: to scale up the cluster where they are or to wait for the main Data Center to be back up and failback the clusters to the original state. At this point, we need to know if the principal Data Center is recoverable and when. My recommendation is to test the failover (automated or manual) and measure how long it will take us to do a failback or to scale up the clusters in the secondary site in order to have enough data to help us take the decision when the moment strikes.
Since there is no tie-breaker and we don’t want a split-brain situation, before failovering to the secondary Data Center, it is important to make sure the main Data Center is really down and no services are accessing the clusters there. We also need to ensure the servers won’t be powered on when the main Data Center is up again.
Although all the failovering processes can be automated, we might want to leave the final decision to a human on critical systems.
If you want to really go full-automated, consider having periodic server health checks according to predefined parameters such as: reachable services from an external point, DNS resolution, network traffic, storage access. And, most important, always use a combination of them.
Network
Our network solution for the Mesos cluster is based on Project Calico, a pure L3 approach without IP encapsulation which ensures very low performance impact and pretty easy troubleshooting. It also provides fine-grained network security implemented by simple policies and optional IP-in-IP tunneling.
Project Calico uses dynamic routing for inter-host container communication, relaying on BGP (Border Gateway Protocol), a routing protocol used by large networks (e.g. ISPs), for internal and external connectivity.
The persistence of its configuration (rules, policies, BGP topology) relays on etcd, a simple and secure key-value store written in Go. This centralized configuration gives our Mesos cluster the elasticity we need when adding/removing agents (adjusting to the demand), in case we have to replace master nodes and last but not least, when we want to change the topology (e.g. activating full-mesh, using IP-in-IP encapsulation, etc).
Let’s take a deeper look at the diagram below:
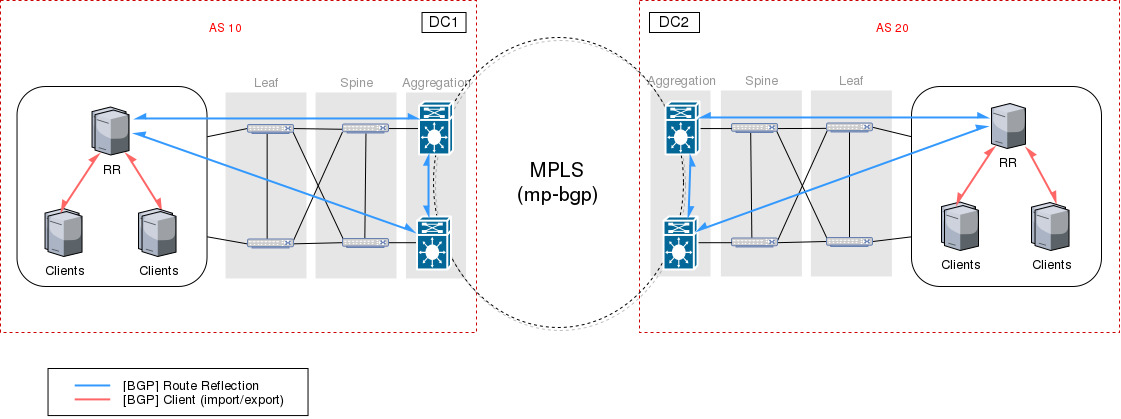
Consider this on-premise architecture between Data Centers where each site has a Leaf and Spine topology with BGP in the Aggregation Layer. Thanks to Calico’s centralized configuration we can easily add the physical routers as part of our SDN topology so the Route Reflectors in each Data Center will peer with them using the right AS (Autonomous System).
In the presented topology, the routers in the Aggregation layer are BGP Route Reflectors connected to the other Data Center using an MLPS backbone (or any other inter-Data Center topology) and each site has an AS number, thereby using eBGP between sites and iBGP between nodes and routers on each site.
By default, Calico comes configured for a full-mesh topology, where each client shares its routes to every other client in the network. As you can tell, the number of connections grows quadratically with the number of clients, which makes it very hard to scale, being highly unrecommended for more than 50 clients. Despite its limitations, disabling Calico’s default node-to-node mesh is a must to allow every server to peer with a Route Reflector. Configure the BGP Peering in Calico is very straightforward following their documentation.
As the diagram shows, we’ve deployed Calico’s Route Reflectors on both sites so we can add/remove clients automatically (the node registers itself in etcd), without modifying the physical Routers’ configuration.
etcd
As mentioned before, Calico uses etcd as backend, so to avoid a SPOF, we’ve deployed a three-node cluster with two nodes in the main Data Center and the other in the secondary one.
etcd failover tasks:
- Add the following line to /opt/stratio/etcd/conf/etcd.conf:
ETCD_FORCE_NEW_CLUSTER=true - Restart the service:
systemctl restart etcd - Then remove the line from the first step.
etcd failback tasks:
- For each etcd node in the main Data Center:
- Add node to etcd:
etcdctl member add server-n https://server-n.fqdn.com:2380 - Add the master address to the initial cluster in /opt/stratio/etcd/conf/etcd.conf:
ETCD_INITIAL_CLUSTER=”master-n=https://server-n.fqdn.com:2380, …” - Comment line starting with:
# ETCD_DISCOVERY_SRV=… - Restart service:
systemctl restart etcd - Remove the line:
ETCD_INITIAL_CLUSTER=”master-n=https://server-n.fqdn.com:2380, …” - Uncomment line starting with:
ETCD_DISCOVERY_SRV=…
Mesos
As expected, Mesos is deployed in an HA mode (multiple Master nodes) with the majority of nodes in the main Data Center and the minority in the secondary. Please note that Mesos HA mode relies on Apache ZooKeeper for both leader election and detection.
All Agent nodes are tagged with the attribute ‘datacenter’ for the frameworks to identify the agents in one or another Data Center and implement their strategy accordingly. These nodes can be distributed unequally (just to be able to run the critical services) and scale up the secondary Data Center during the failover.
Remember to deploy Public Agent nodes on both sites to allow North-South load balancing for tasks on both Data Centers.
Mesos failover tasks:
- Edit /opt/mesosphere/etc/master_count and change it from 3 to 1.
- Edit /opt/mesosphere/etc/mesos-master and change the MESOS_QUORUM from 2 to 1.
- Restart service:
systemctl restart dcos-mesos-master
exhibitor failover tasks:
- Edit /opt/mesosphere/etc/exhibitor and change the EXHIBITOR_STATICENSEMBLE by deleting the IPs of the main Data Center’s servers.
- Restart service:
systemctl restart dcos-exhibitor
mesos failback tasks:
- Edit /opt/mesosphere/etc/master_count and change it from 1 to 3.
- Edit /opt/mesosphere/etc/mesos-master and change the MESOS_QUORUM from 1 to 2.
- Restart service:
systemctl restart dcos-mesos-master
exhibitor failback tasks:
- Edit /opt/mesosphere/etc/exhibitor and change the EXHIBITOR_STATICENSEMBLE by adding the IPs of the main Data Center’s servers.
- Restart service:
systemctl restart dcos-exhibitor
Marathon
The marathon framework provides constraints that will help us deploy Apps across Data Centers.
Let’s say we’ve deployed our agents with the attribute “datacenter” and a value of “main” or “secondary” depending on the Data Center in which they are located.
Three operators are worth mentioning for this purpose:
CLUSTER:
Tasks will be launched on agent nodes which attribute match exactly the value. In our case, we might want to pin non-relevant tasks to the main Data Center, so the secondary Data Center won’t have to take its load in case of a disaster.
e.g.:
To launch tasks only in the main Data Center:
“constraints”: [[“datacenter”, “CLUSTER”, “main”]]
MAX_PER:
Tasks will be launched with a limit per value of the attribute.
e.g.:
To launch at most 2 tasks per datacenter:
“constraints”: [[“datacenter”, “MAX_PER”, “2”]]
GROUP_BY:
Tasks will be launched evenly distributed across agents with different values for the attribute (it is highly recommended to check the documentation for this operator).
e.g.:
To launch tasks distributed through both Data Centers:
“constraints”: [[“datacenter”, “GROUP_BY”, “3”]]
Conclusions
We’ve presented a multi-datacenter deployment for disaster recovery in two Data Centers (main/secondary) with easy failovering using Project Calico as SDN. With this approach we have at least one Route Reflector on each site, which allows us to dynamically add or remove clients (that is, Mesos Agent nodes).
We’ve also gone through some strategies for Marathon using operators with attributes, which can be implemented in any custom framework.
The failover can be fully-automated if desired, but it is not recommended since it may lead to an undesirable state of the cluster in case of a false positive in the checks, which can be very hard to recover.
That’s all for now, I hope you’ve enjoyed it, and if you have any trouble testing or deploying this architecture, feel free to leave a question in the comments.


