
Limitations of stateless services
Over the last few years and even now, we usually hear that in order to build a microservices architecture or any distributed system, the services must be stateless. This way if we need, we can scale out adding more instances to face all the traffic that arrives. However, these systems also need to store the state in some way. And how do they do it? Well, because they can not store it in the service itself, it has to send it far away from the logic that must have to process it. Normally this datastore can be either a relational or document database.
This separation of logic and data brings a great performance loss because each request implies at least two (but usually more) trips between the service and the database instance. First of them, to retrieve the actual value of the state and second one, to store the updated state obtained after the logic process. The latency added because of these two calls plus the fact that the database instances are fewer than the services and that the databases usually use locks at row or table levels to ensure integrity among other services requests, create a bottleneck that limits a lot the performance and the throughput of the whole application.
Later we will explain how we can address these problems using stateful services that could manage distributed state at scale.
Limitations of FaaS
One of the biggest goals achieved by public clouds to software development in terms of cost saving, application maintenance and deployment automation are the known as serverless services. The first services of this kind and also the most popular are the ones called Functions as a Service (FaaS). Because of that there are still a lot of people among IT professionals that think that these two terms are the same. But they are not: the term “serverless services” stands for a kind of service that hides all the complexity associated with the deployment away from the developer. They also offer a dynamic autoscale depending on the amount of work, causing even to scale it to 0 if there is not any request to serve.
On the other hand, although FaaS has also these features, they narrow a lot the use cases they can handle because they are stateless- They have a limited time to execute and they cannot be called directly but indirectly through some kind of trigger like event queues. These limitations make FaaS good for some use cases but not for general purpose applications.
Stateful Serverless Services to the rescue
After reviewing all the limitations of modern distributed systems both to manage distributed state and also to hide the complexity of deployments and autoscaling, we can point out all the features that an optimal solution must have:
Stateful long-lived addressable (location transparency) components
These components would be the equivalent to FaaS functions but without their limitations. In other words, these components could do computational costly operations and could be called directly, but also they could be automatically scaled out . Actors are good candidates for this type of component.
Option for distributed coordination and communication patterns like point-to-point, broadcast, aggregation, merging, shuffling, etc.
To achieve this, it would be interesting to have an orchestration system that allows the services to communicate among them using all these communication patterns. For example, a container orchestration tool like kubernetes could do the trick.
Manage distributed state at scale and reliable and physical colocation of the state and process
It is logical to think that having physically near the process and the state is a good idea in terms of performance. And this is the same idea behind the creation of stored procedures in databases: they may not be the best approach for decoupling but they are amazingly fast.
Because of that, to manage distributed state and to achieve physical colocation of the state and process (in other words, to have stateful services) we have two options: to use event sourcing or to use CRDTs. These two options give us the choice to choose between the strong consistency provided by event sourcing or the eventual consistency provided by CRDTs.
The following is a more detailed explanation of why these are the best two options to manage distributed state at scale:
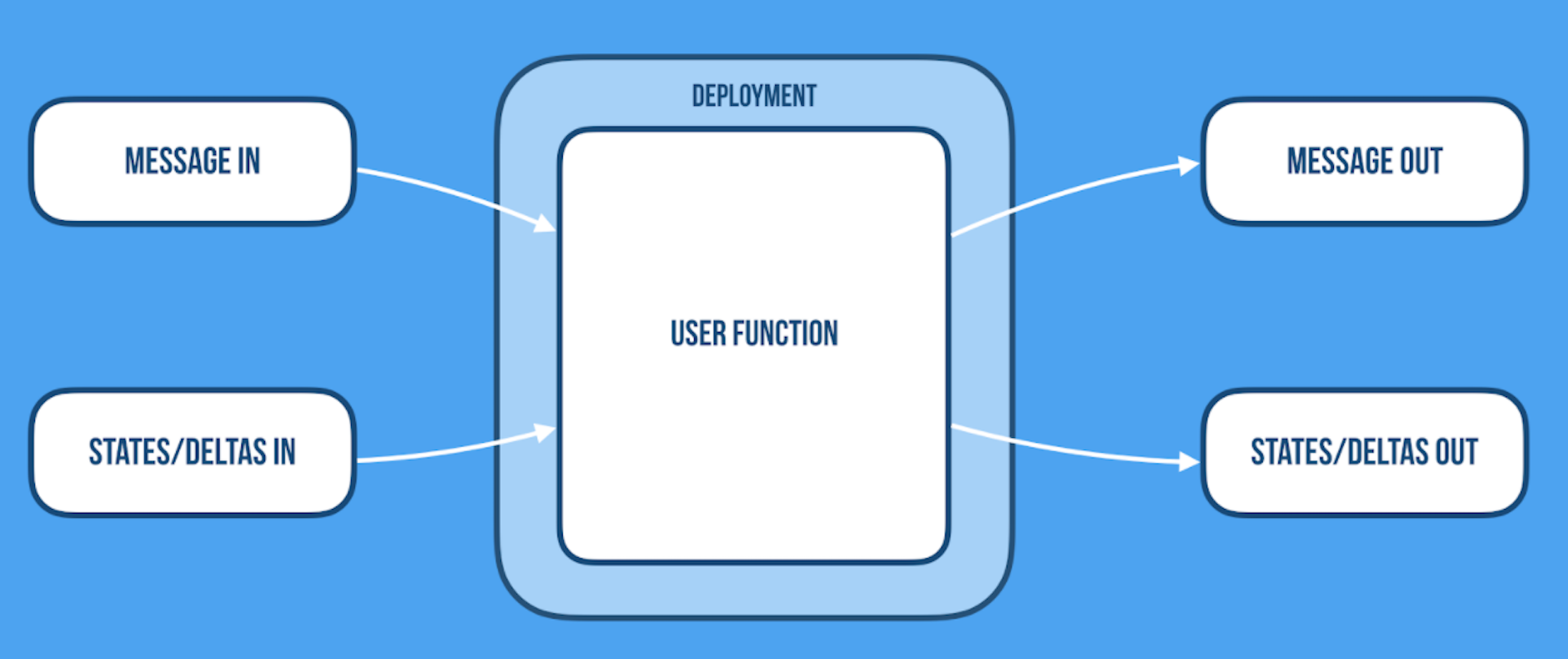
Event sourcing: The state is built by applying inmutable events in order. Because of this, to recreate the state of a specific entity all you have to do is to replay all the events related to that entity in the same order that were produced. The way an event sourcing service would work is: the service should have the final state of the entity that will be processed and will be updated with each new event. When a new request comes, the related logic will be executed and a new event or events will be appended to the entity event log. If a new instance is created or if an existing instance is restarted, all you have to do is to reprocess the event log in order to achieve the current state.
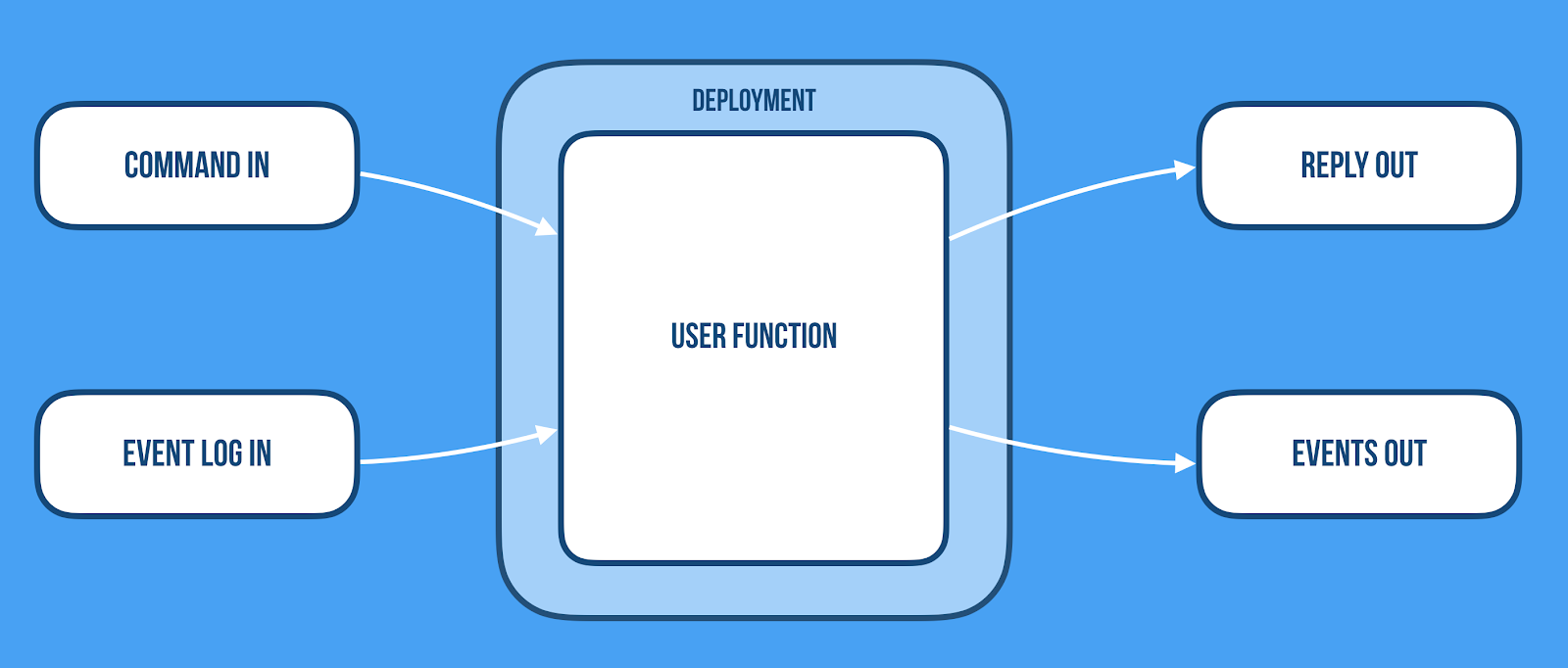
CRDTs: Conflict Free Replicated Data Types are data structures with a merging function associated with it. This function must have the following properties: associativity, commutativity, and idempotence. Having all these properties assures us that the state will always converge when merging different state instances of the same entity through the merge function.
The way a CRDTs service would work is: The service should have the current state of the entity and it will be updating it by applying the merging function when another instance updates its own copy. Then, when a new request comes, the service first will process it, then it will update its copy and will broadcast the new update (delta) to the other instances of the same service that will apply the merging function. Eventually all of them will converge to the same state.
Ligthbend’s solution
Lightbend, the company behind Scala, Akka and Play among others have created a specification and reference implementation to address the problems exposed above by defining a solution based on serverless stateful services called Cloudstate.
Cloudstate fulfills all the identifying features to provide an optimal solution. The stack of tools that it uses is the following:
– Kubernetes as a container orchestrator that provides facilities to implement different communication patterns among the services (point-to-point, broadcast…)
– Knative provides a way to autoscale and to hide the complexity of deployments of serverless services.
– An Akka cluster instance as a sidecar container inside every service pod. This Akka instance will form a cluster with the rest of Akka sidecars of the pods of the same service. This cluster will be responsible for managing distributed states at scale, the perfect task for Akka. It will keep the state consistent among all the instances and will store it in a datastore as a backup asynchronously. It also will manage the internal and external communication with other services.
– GRPC Protocol is used in the communication between services and Akka cluster sidecars. This enables the services to be polyglot. The only need is that there exists a library to communicate over the GRPC protocol.
– GraalVM: using GraalVM instead of JVM allows services to start much faster. This way the deployment and scaling time is much lower and thus the performance is better.
Here is a diagram with the architecture of the solution proposed:
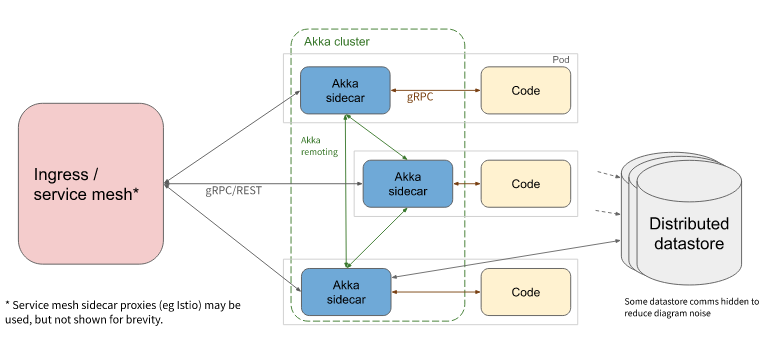
Thanks to this design, Lightbend has achieved a solution that probably will give birth to the new generation of serverless services or what they want to call “serverless 2.0”. Opening the serverless world to stateful services could implement more general use cases than the actual FaaS does.
Next steps
Currently this specification and reference implementation is still under development and Lightbend is actively seeking contributors that want to collaborate on it. Some of the next challenges they will have to face are to support more languages like .Net or to increment the number of datastores suitable to store the state as a backend like Cassandra.


