
Let’s imagine that you want to buy a new car, and you fall in love with this new car’s brand. Because you really want that car, the car’s brand comes out everywhere in your daily life, even though the amount of these cars remain the same. Our brain is trained to focus on what it wants to see.
As we have already seen in the previous posts, Deep Learning was inspired by biological systems (neurons and memory). Using what we learnt from Cognitive Sciences we’ve replicated it somehow in an artificial world. We already highlighted that Neuroscience and Deep Learning are very different disciplines, but it is very interesting to state what similarities we find in the cognitive (biological) system with what we have learnt from the functioning of deep (artificial) Neural Networks. Addressing this knowledge would greatly help us to better understand both concepts and their motivation.
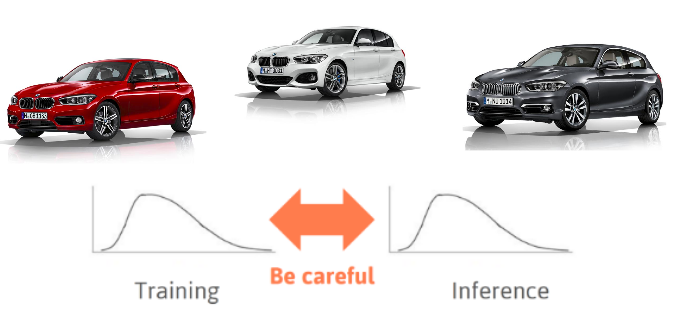
Ok, let’s now imagine that you have a dataset that contains different cars, and like the majority of real-world dataset, are unbalanced. Therefore, you need to improve our training data. Our dataset could contain more examples of our favorite brand, this will have an impact on the way the model predicts at the time of inference. Likewise, even if we have our dataset balanced and most of our favorite cars are the same color, the similar thing will happen. In this way, we will also get confused when we see another car of the same color because we will think that this might be our favorite car. Convolutional neural networks might have a related problem. This happens because that’s how machine learning algorithms work. There are many factors here, but Deep Learning will merely learn the bias.
Invariance
Invariance is the ability of convolutional neural networks to classify objects even when placed in different orientations. The best way to achieve this will be with data and just more data! Sometimes we are simply unable to collect more data… but we do have several mechanisms to increase a training dataset.
Let’s first empathize with this concept from the human perspective – a biological neural network. Take a look at the next picture:
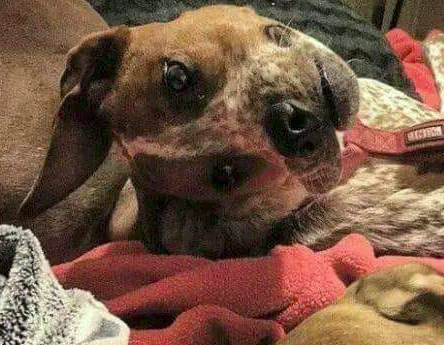
What do you see in this picture? Why is it so hard for us to identify what’s in this image? This has all to do with the way we’re built. Our brain has evolved to try to find logical solutions and, as we are all used to see two eyes and a mouth when we see a face, we will try to find something that will probably lead us to discover a completely normal dog with a tilted head.
In the same way, we learnt that convolutional neural networks are invariant to:
- Scale? No
- Rotation? No
- Translation? Partially
Data Augmentation
Data augmentation is a basic technique to increase a dataset without new data. Although the technique can be applied in a variety of domains, it’s very commonly used in computer vision, and this will be the focus of the post.
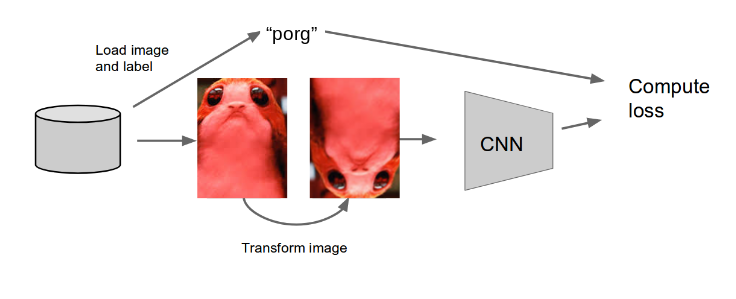
The benefits of data augmentation are two:
- The first is the ability to generate ‘more data’ from limited data
- The second one is to avoid overfitting: For a network it is somewhat problematic to memorize a larger amount of data, as it is very important to avoid overfitting. This occurs because the model memorizes the full dataset instead of only learning the main concepts underlying the problem. To summarize, if our model is overfitting, it will not know how to generalize and, therefore, will be less efficient.

Take a look at the image and get creative! Mix of: translation, rotation, stretching, shearing, random erasing, adding noise, lens distortion… and go crazy!
Moreover, there is another type of data augmentation which is also very typical. It’s called: Test Time Augmentation (TTA). In this case, we need to do something similar. However, when the model has to be applied to a specific image in the test set, instead of using the image as it is for inference, the same transformed image has to be used in several ways, by calculating the average of the results obtained. Hence, accuracy could be increased.
To conclude, it is clear that Image augmentation is simple to implement (tensorflow, keras, pytorch and others make the work easier). Furthermore, we can even use it on the fly. On the other hand, as we have seen, Data Augmentation helps to prevent overfitting, by being especially useful for small datasets. It should be pointed out that you cannot use all the possible types of augmentation, which is why for better results we need to use the right kind of augmentation. In addition to this, you could consider to try a more complex data augmentation technique (like coordinating variables, per-pixel classification, etc). At the same time, data augmentation is not a “silver bullet”, its usage depends on the data and the nature of the problem, for instance diagnosing a certain disease.
If you want to learn more about Deep Learning and Data Augmentation, take a look at this Data Science Meetup we organized at Campus Madrid:


