This is the second post of our Wild Data series. In this post, we are going to expose how to transfer style from one image to another. Here, the most interesting point is to know that we won’t use a neural network to classify a set of classes as usual. I mean, we don’t need to train a network for a specific approach. Transfer style is based on pre-trained networks such as it could be a VGG19 trained with ImageNet (one million of images). Thus, a good understanding of transfer style will help you to better understand how convolutional neural networks works for vision. Let’s go on!
Transfer Style
The main idea/solution is very intuitive:
1. Let’s extract content from an original photo.
2. Let’s extract style from a reference photo.
3. Now combine content and style together to get a new “styled” result.

How do we really get these results? We start from a noise image, and in each epoch in which the algorithm combines both images, we are simply taking advantage of backpropagation to minimize two defined cost function values (content and style). Since we have a total loss function that depends on the combined image, the optimization algorithm will tell us how to change our noise image, in order to obtain a combination image to make the loss a little smaller.
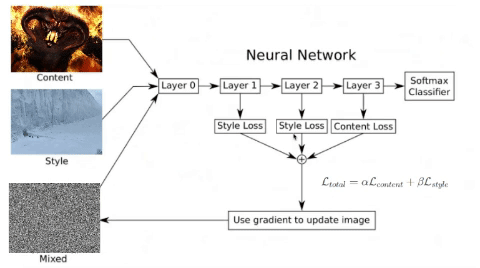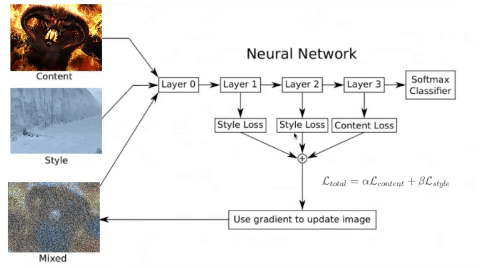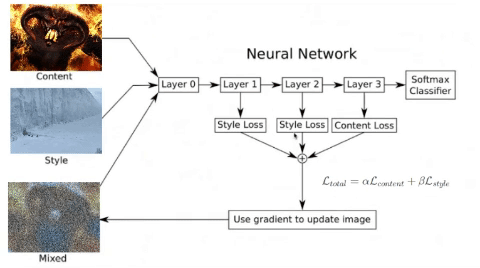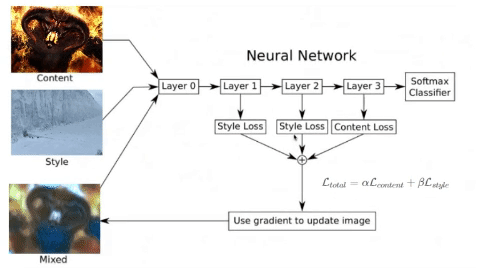
You may wonder why we use the results of the middle layers of a neural network to classify previously trained images to calculate our losses in style and content. That’s why, the network has to understand the image to perform the function for which it was built and trained. Thus, among all the layers between the input and the output, the network is doing transformations to convert the image pixels into an internal understanding of the image content, and we can use it to extract content and style.
In most cases, what is more typically used is gradient descent: by using first-order methods, on which backpropagation can be applied, or by using second-order methods, based on the hessian or an approximation of it (for instance, information from the second derivative). In addition, we could apply numerical methods to do this without the need to calculate the exact hessian (because it has a quadratic complexity and is very complicated). Besides, it should be pointed out that each method will have a different image result.
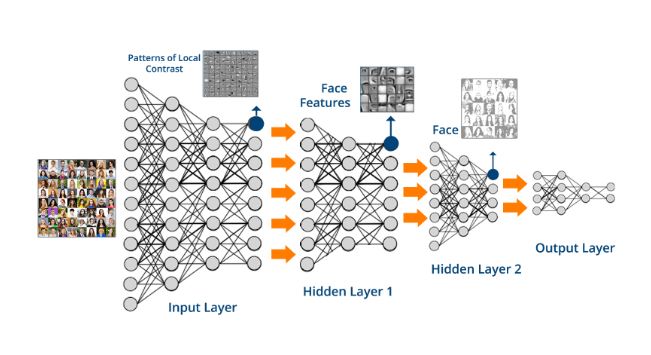
One of the most fascinating concepts about deep learning is that each layer gets a data representation focused on the objective of the problem to be solved. Here, the network as a whole generates an idea derived from different faces. Thereby, lower convolutional layers capture low-level image features (for instance, edges, textures and colours) while higher convolutional layers capture more and more complex details, such as face features and, at the end, different faces.
As you can see, last layers contains these internal understandings of the content of the images. If we go through the previous neural network with two different images of faces, this internal understanding will be very close because the activations have been similar. Therefore, euclidean distance between the intermediate representations will be lower, and this is what will be used to bring the noise image closer and closer to the reference image in each epoch.
Before, we have tested what an ice Balrog might look like. Likewise, we are going to continue with what would happen if we combined Khaleesi’s face with a white walker’s face. Don’t worry, no spoilers of Game of Thrones here:

Epic fail! it is all due to the way in which the style was transferred through gram matrix (we could use other methods as well), by using correlation in the way of multiplication between different weight values in the filters. Therefore, information about the semantics of the image was lost, because of retaining just basic components of the texture/ambiance/appearance, in contrast, we cannot transfer the blue color of the eyes.
In conclusion, transfer style is always interesting to better understand the nuts and bolts of convolutional neural networks, and it might be interesting in topics related with data augmentation. But, this approach probably will not be enough to address these problems and often, the results are… too artistic, although it is true you could ensemble them with others methods to improve the results. We could also introduce the awesome GANs, which deserve a whole new post. And…just one more thing, keep in mind this quote from Hacker Moon that I really like: “If you really think about it, all human evolution is really nothing more than abstracting problems and automating solutions to earlier problems, which leads to new problems and new solutions in a never ending cycle”.
If you want to learn more about Deep Learning, Data Augmentation and Transfer Style, take a look at this Data Science Meetup we organized at Campus Madrid:
– Video
– Presentation


