
Stratio has created a new user interface that allows you to work without writing a single line of code, which means that no programming skills are needed nor to use advanced technologies such as Spark, Scala, HDFS, or Elasticsearch. Developers, Architects, BI engineers, data scientists, business users and IT administrators can create data analytics applications in minutes with a powerful Spark Visual Editor. Welcome to Sparta 2.0, a brand-new version of Sparta born with the forthcoming release of the Stratio Data Centric Platform.
Stratio Sparta 2.0 is the easiest way to make use of the Apache Spark technology and its entire ecosystem. Create one workflow and start gaining insights from the data!
The main features and advantages that the users obtain when using the application are:
- Code-free Big Data applications for everyoneThe user-friendly Visual Build Tool makes it easy to develop Big Data applications based on Spark.In the following gif you can see how to create a Spark application in just one minute!
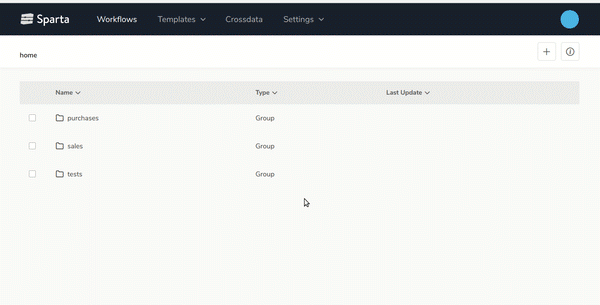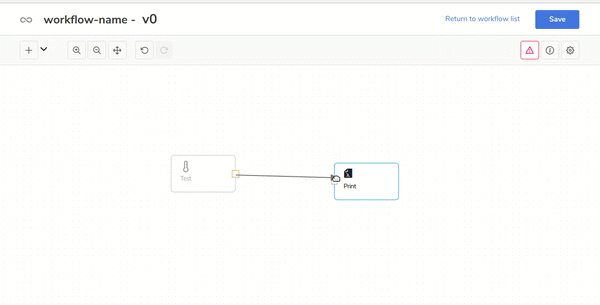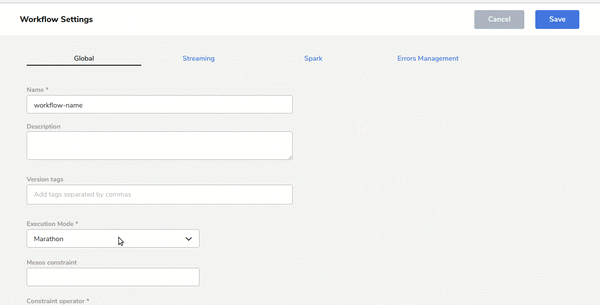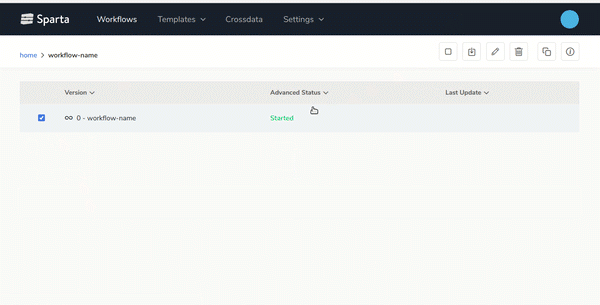
- Multi-Engine definition and deployment of Streaming and Batch workflowsBatch and Streaming Spark APIs are available with visual components in order to build real-time data pipelines or programmed batch processes.The Sparta DAG and workflow executor is agnostic to the execution mode, in the future the Sparta Team, Stratio Partners or the Community will integrate more distributed frameworks such as Flink or Kafka Streams.
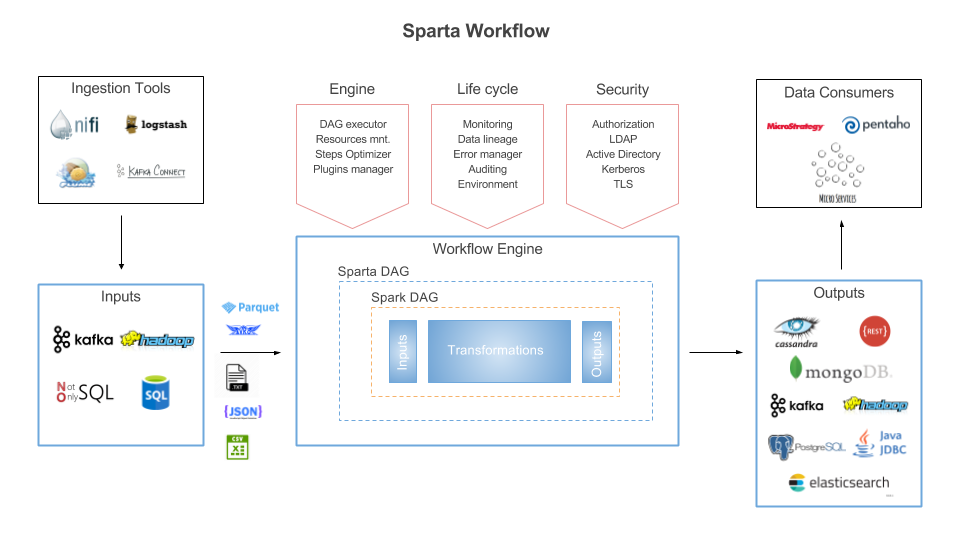
- Ready-to-use workflow steps (Inputs, Transformations and Outputs)To use one of the several already implemented inputs, transformations or outputs, just drag and drop their corresponding box into a canvas. The data transformations parse and process the incoming data with structured or unstructured formats: json, csv, avro, txt or tables from SQL or NoSQL databases. After that, execute selecting, filtering or advanced SQL analytical operations over the transformed data and storage all the workflow steps in one or more outputs.The inputs, transformations and outputs already supported are:
○ Streaming
◊ Inputs: Kafka, HDFS-compatible file systems and SQL over multi-datastores with Spark SQL integration and incremental querying.
◊ Transformations: Avro, Casting, Checkpointing, Csv, Cube, DateTime, Distinct, Explode, Filter, Intersection, Json, OrderBy, Persist, Repartition, Select, Split, Trigger, Union, Window.
○ Batch
◊ Inputs: HDFS-compatible file systems and SQL over multi-datastores with Spark SQL integration.
◊ Transformations: Avro, Casting, Csv, DateTime, Distinct, Explode, Filter, Intersection, Json, OrderBy, Persist, Repartition, Select, Split, Trigger, Union.
○ Streaming-Batch
◊ Outputs: Elasticsearch, MongoDB, Redis, Parquet, Postgres, JDBC, CSV, Kafka, Avro, HDFS-compatible file systems and others Spark SQL connectors.
- Extensible componentsAll the workflow steps are customizable. An advanced user can extend the native components and adapt the workflow to the project building custom inputs, transformations and outputs and use them on the user interface.With a basic knowledge of Scala you can create one custom step extending the SDK and implementing only one function. After building the jar with the code, Sparta makes your code available in the workflow and throughout the entire Spark cluster.
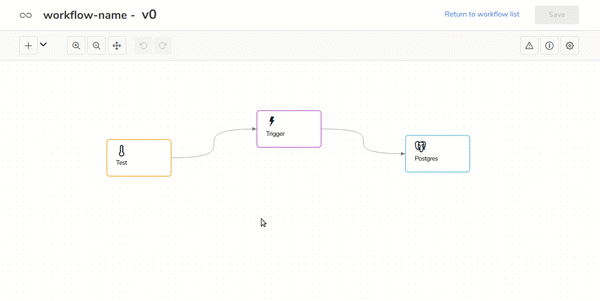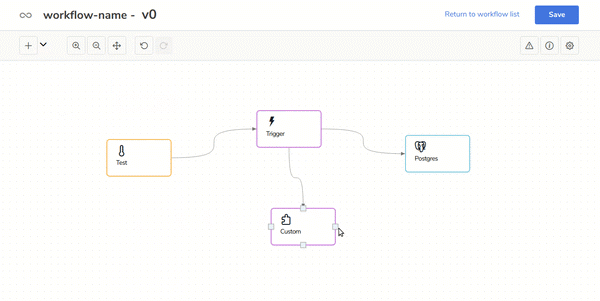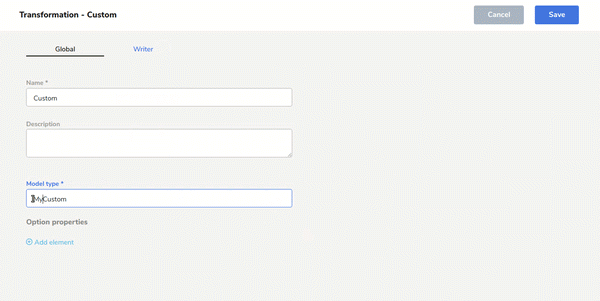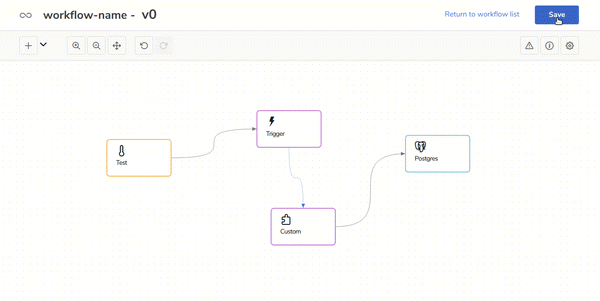
In the following gif you can see how to use your own Scala code in the workflow:
- SQL integrated on Streaming and Batch applicationsFully-SQL integration in Streaming and Batch workflows. One easy language available on inputs and transformations that allows you to create alerts, rules or aggregated data useful for constructing advanced real-time dashboards.On the next gif is possible to see how to join streaming data with static data with SQL:

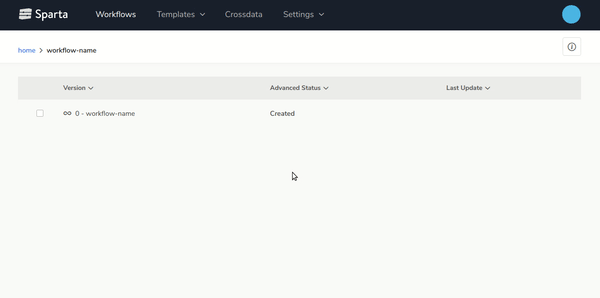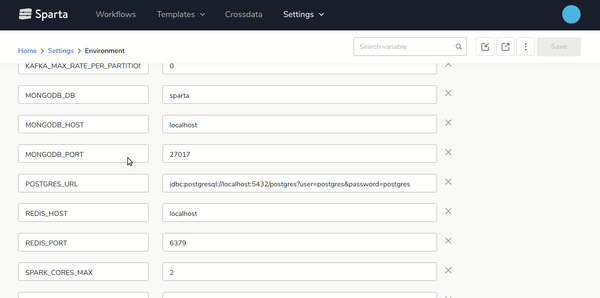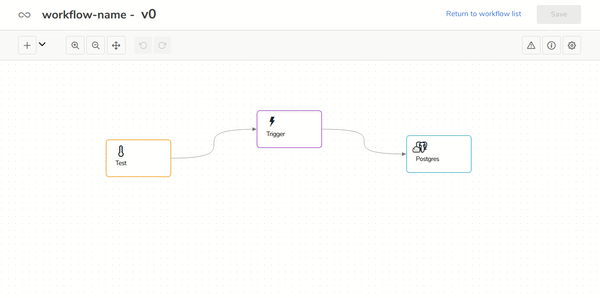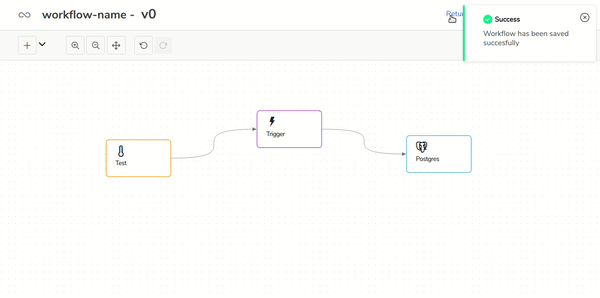
- Easy workflow deployment and monitoringDesign, configure and deploy multiple workflows with few clicks and monitor it on the Sparta user interface:
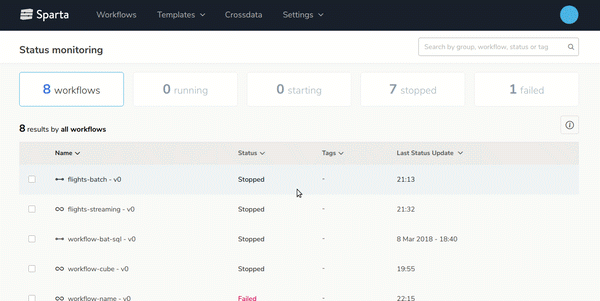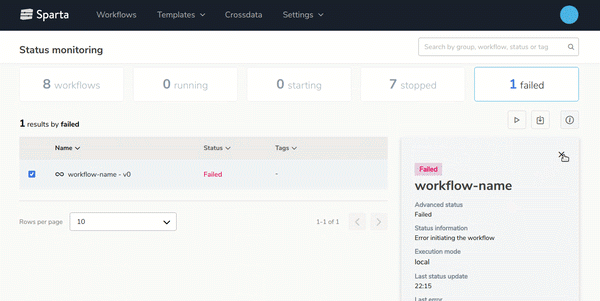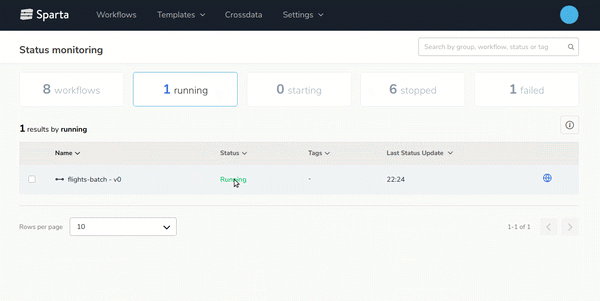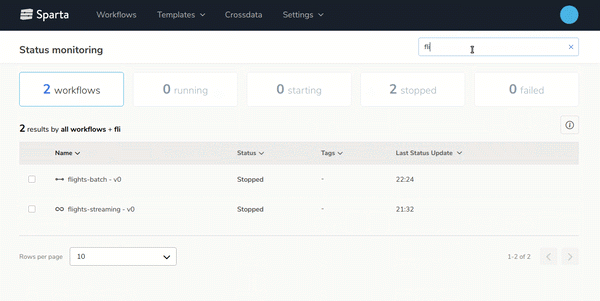
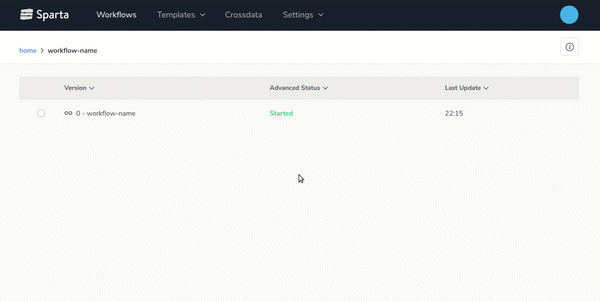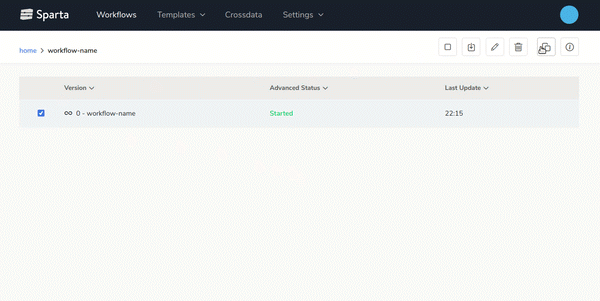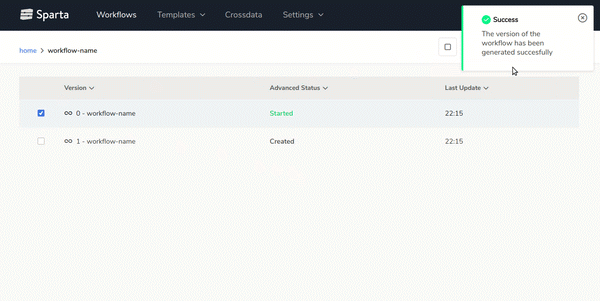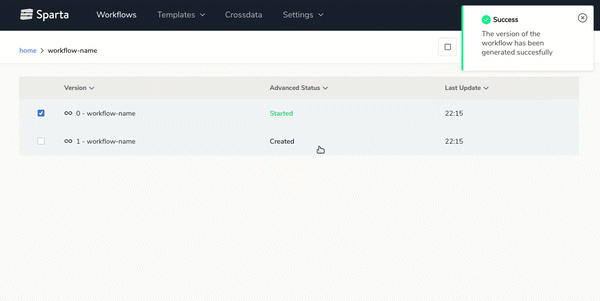
- End-to-end Big Data applications lifecycle managementBuild, version, test and deploy workflows over any environment easily.On the next gif you can see how to generate new versions of the workflows with 2 clics:
By making the environment deployment easy, you can create variables that can be used in all the properties, with this tags system you can create workflows that obtain the BBDD connections or the Spark resources from the environment variables.
On the next gif is possible to see how to use environment variables in the steps with Moustache syntax:
- Authentication – Authorization – AuditFully secured data pipelines end-to-end. Integrated with Mesos security; Postgres, Kafka and Elasticsearch security by TLS; Zookeeper and HDFS by Kerberos.All user actions in the UI are integrated with the authorization system.
- Data Governance integration in the Spark applications
Integrated with the Stratio Data-Governance solution, you can see the data lineage of the workflows deployed in the Spark cluster.
Sparta is based on the brand-new technologies of the Big Data ecosystem:
○ Scala
○ Akka
○ Angular
○ Spark
○ Mesos
○ Marathon
○ Zookeeper
The workflows are deployed as Marathon Applications: the application executes a spark-submit in client mode over Mesos and then the workflows are monitorized with Zookeeper.
Multi-tenant servers and Multi-datacenter deployment are supported over the Stratio EOS architecture. In the following image you can see the architecture:
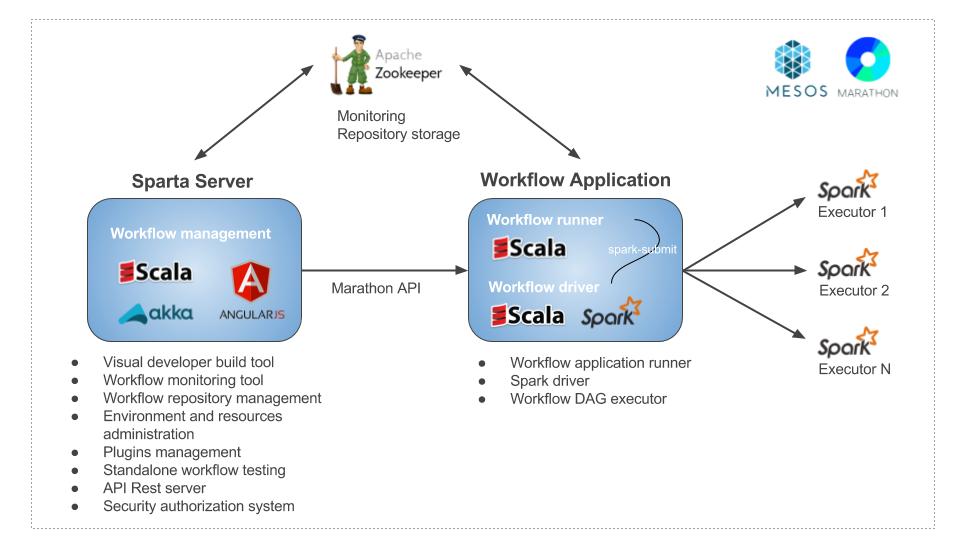
Sparta is based on the creation, execution and monitoring of workflows. In a Big Data architecture, Sparta could be integrated with the following technologies:
After three years of hard work, we have came so far but there is still so much work to do. Our next steps will be to improve the monitoring section, integrate transactional writes, integrate continuous deployment tools, improve the reprocessing mechanisms and error management or integrate orchestration sentences over workflows or group of workflows.
I don’t want to finish this post without saying congrats to all the team members of Sparta: Max Tello, Francisco Javier Sevilla, Javier Yuste, Francesca Pesci, Sergio del Mazo, Diego Martínez, Pablo Fco. Pérez and Gastón Lucero. Without their great work and effort, this would not have been possible. Thanks!


