
Have you ever watched the cooking teaching shows? You have probably noticed that chefs have usually already all the ingredients separated and chopped. A chef probably will be more useful and creative cooking rather than spending time peeling and chopping potatoes, even though it is still important in the recipe. Likewise, a data scientist will be more useful and creative building models rather than spending time with data preprocessing. In this way, where a chef would prepare exquisite delicacies a data scientist prepares succulent models.
Most companies are already aware of the potential of data and are therefore concerned about storing it to draw out as much intelligence as possible. As we all know machine learning is not magic, organizations accept that they need to hire the services of data scientists and what is involved in all these machine learning services? Let’s take a look at the data collected by Quora’s A2A (Ask To Answer):
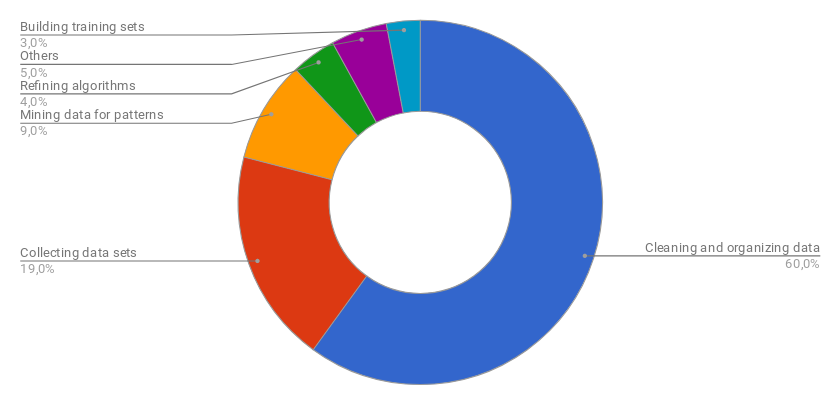
It would seem obvious that data scientists would spend much of their time building these machine learning / deep learning models, but data preparation takes almost 80% percent of the whole analytical pipeline in a typical project.

A dataset comes from all kinds of sources. You can gather it from internal warehouses, external APIs and just about anywhere. In addition to this, as can be seen from the graph, there are a multitude of operations such as normalization, testing and recording to ensure that all data sources remain consistent while projects are kicking off. A fundamental principle of data processing is the GIGO cycle, short for ‘Garbage In Garbage Out’.
Data has indeed become the basis for competitive advantage but it cannot be left in it’s raw, unrefined state. Most datasets are tainted by very bad data and the only way to find the data correctly is by turning to the world of academics. What good would it do to have petabytes of data if there is a large amount of duplicate, incorrect or incomplete data? You have to assume that the data, whether structured or not, will have to be prepare it (transformations, aggregations and data cleansing) even those acquired through IoT. In addition, these tasks could be very difficult to sniff out, even if it is carried out on an ongoing basis; it could therefore be one of the greatest challenges currently faced by organizations when extracting intelligence from Big Data. One should not be sceptical about this term, as even Apple was forced to apologize for this. No matter how many data scientists there are on our team, no matter how excellent they are, they can’t be sure they are drawing good conclusions about consistent data.
The need to be able to quickly manage and analyze large volumes of data often obstacles the way of providing seamless data delivery to the Big Data environment. It is therefore essential to be aware that if we want to be more competitive when developing machine learning models we have to speed up possible bottlenecks as much as possible. Hence, a Data Centric architecture provides a unique data vision at the center with models (and other applications as well) around it, putting that data to work in real time with maximum intelligence.
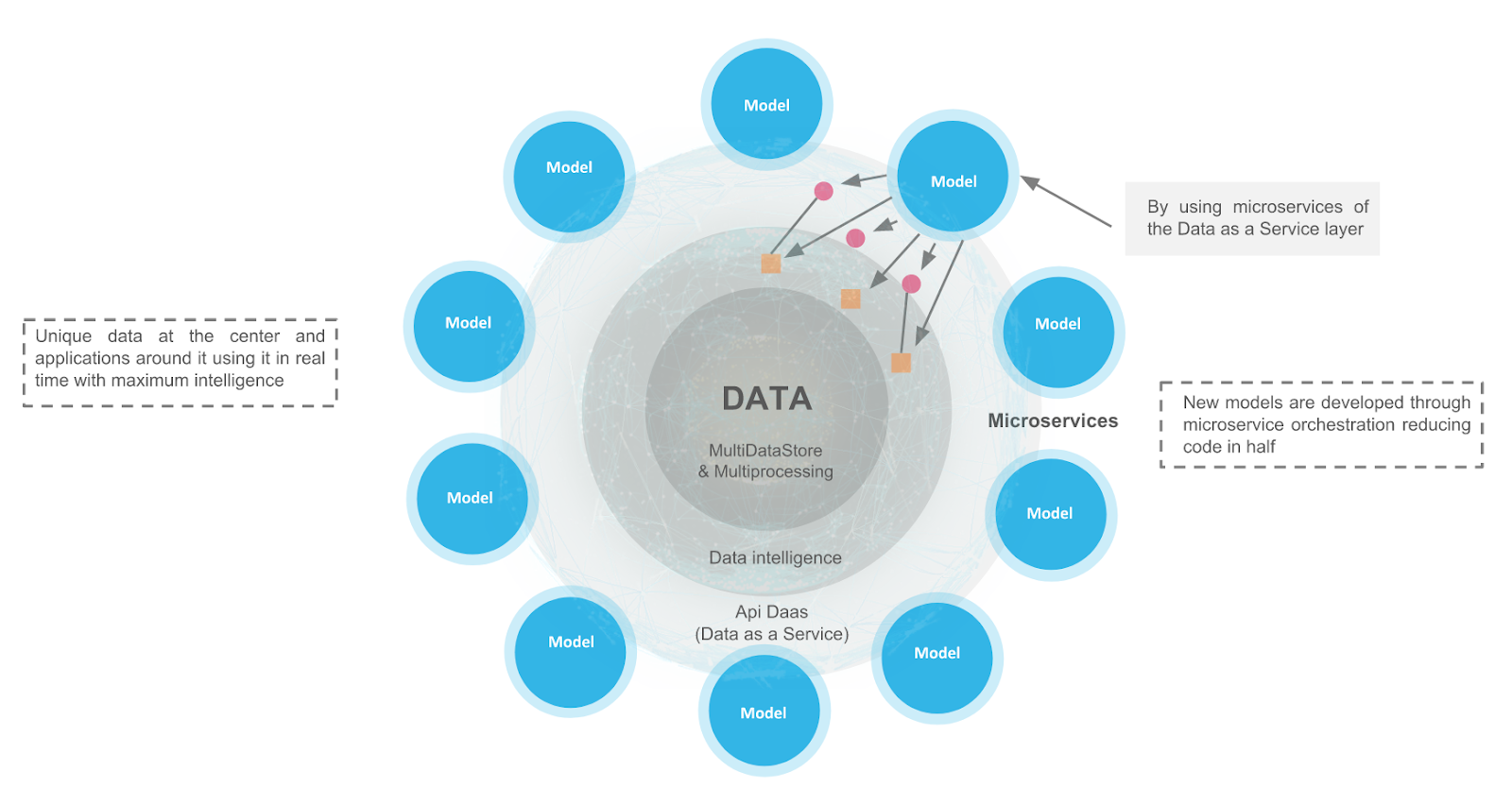
Let’s go on with some of its modules:
- XData: Centralized vision which provides a simple but powerful layer that allows you to combine the analysis of information from different databases, independent of the underlying datastore technology.
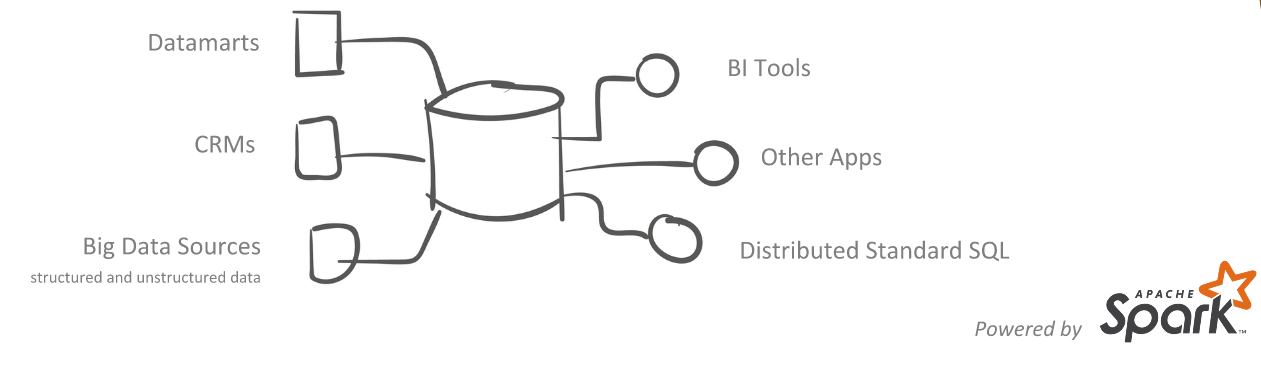
- Sparta: Creates the workflows to automate the data cleaning, staging and health checks of data to store raw data and aggregated data in real time through distributed environments, with as many views of the data as necessary, in the same time as we would have previously spent locating each one of the datasets. Stratio Sparta 2.0 is the easiest way to make use of the Apache Spark technology and its entire ecosystem without writing a single line of code.
- Governance: Nowadays, data governance importance has drastically increased inside companies of all sizes. This is due to the big impact that data management have on decision making: there are no policies or processes that allow granting the data reliability.If there is not a defined govern or a data responsibility structure, the data will be rarely checked and often redundant, incomplete and not up to date.
Thereby, Stratio Data Centric is able to significantly cut down on 80% of time in data preparation by using a totally integrated platform. This would be as if a chef had a large supermarket in his pantry ready to prepare his recipes.
Finally, personally speaking about the machine learning cycle, although exploratory data analysis should be the best starting point to look for hypothesis about the data, sometimes it is during the modeling phase itself where the resulting new insights may change the initial hypothesis, and where better hypothesis arise. Therefore, it is probably worth spending less time on other phases and more time on the actual modeling phase instead. One of the benefits of doing this is avoiding attractive but inefficient or inappropriate models. Thereby, Stratio Data Centric not only allows you to efficiently store data by providing a unique vision, but it also allows you to easily automate some of these “boring” machine learning tasks making it easier to focus on being more competitive.


