
MesosCon Europe was held in Amsterdam from August 31 to September 2 and a small representation of Stratio’s crew was over there.
Benjamin Hindman’s opening keynote
Mesosphere’s Co-Founder & Chief Architect Benjamin Hindman broke the ice with the first keynote.

After talking about the mesos ecosystem’s growth within the last months, he explained the nested containerization model and the improvements in the Mesos resource allocation. He then introduced an African nonprofit organization called praekelt.org dedicated to using mobile technology to improve the lives of people living in poverty. A representative from the NGO explained how mesos and DC/OS are a perfect fit for its cluster provisioning. The NGO has to run quite a few clusters where 80% of the setup is identical for each cluster and the remaining 20% is different. They therefore get the most out of mesos and DC/OS by deploying these distinctive features separately. The representative was asked what the Mesos’ biggest deficiency is nowadays. He replied that they were struggling to find a persistence layer that fits their current needs (he pointed out that they are currently using GlusterFS as their persistence backend).
Netflix’s Sharma Podila on stage at Mesos
Senior Software Engineer Sharma Podila at Netflix closed the first round of keynotes. He started by talking about Fenzo, a scheduler java library for Mesos that contains some plugins and strategies that might be used to optimize common tasks when creating a Mesos Framework. At Stratio we were playing around with this library when we created our very own framework for Stratio Decision.
Podila also mentioned Project Titus which is Netflix’s internal container cloud that runs both batch-style jobs and services. A question was raised as to whether Netflix is planning on open-sourcing Titus, but Podila explained that the platform is very coupled to the Netflix architecture.
Mesos 1.0
 After the keynotes, we attended the “Mesos 1.0” talk delivered by Vinod Kone and Anand Mazumbar who both work for Mesosphere. They explained the new release cycle defined for Mesos which aims at releasing a new version every 2 months. Every minor release will be supported for a period of 6 months. More information here: mesos versioning. Their talk detailed the efforts they have been making over the past few months to improve the Mesos APIs and provided information on their brand new (still experimental) Operator API.
After the keynotes, we attended the “Mesos 1.0” talk delivered by Vinod Kone and Anand Mazumbar who both work for Mesosphere. They explained the new release cycle defined for Mesos which aims at releasing a new version every 2 months. Every minor release will be supported for a period of 6 months. More information here: mesos versioning. Their talk detailed the efforts they have been making over the past few months to improve the Mesos APIs and provided information on their brand new (still experimental) Operator API.
The evolution of Deploy Tooling at Twitter

Another interesting speech – “The evolution of Deploy Tooling at Twitter” – was delivered by David McLaughlin. When deploying microservices at twitter, the team met with challenges and made some mistakes.
He pointed out that when you deploy something in production, it is always best to have a simple and fast mechanism to rollback when things do not go as expected.
Regarding Apache Aurora, McLaughlin said that it could be seen as Twitter’s Marathon, although it also supports scheduling batch tasks or cron jobs (as Chronos does). He explained how Aurora is helping Twittter with its Canary deployment which is a production deployment strategy that allows rolling out updates to a subset of job instances in order to test different code versions alongside the actual production job. See the following link for more info: Martin Fowler
McLaughlin also highlighted that Aurora supports preemption in order to guarantee that important production jobs are always running. Check out the following link for further info: Aurora preemption.
The speech ended with a demo of Apache Workflows – Deploying on Apache Aurora at Twitter with the following design goals: introducing a new entity – a Workflow – that captures all testing and release steps, supports and encourages continuous deployment and makes rollbacks a first class citizen of the tool.
Marathon and Chronos
Matthias Eichstedt and Matthias Veit from Mesosphere talked about Marathon and Chronos State of the Art. Marathon ensures long-running tasks are running in the datacenter and is commonly used to maintain high availability of other frameworks. Chronos is the fault tolerant cron of the datacenter. The roadmap for each of these projects revealed that Chronos has been replaced by Metronome, a brand-new Mesos framework for scheduled jobs. If you are interested in this project check out its github: Metronome github. Metronome has been integrated natively with the brand new DC/OS 1.8 and is available on the Jobs tab on the DC/OS UI.
During the lunch break we had a friendly and interesting chat with the people from REX-Ray about our current persistence needs at Stratio.

After lunch, Anindya Sinha from Apple Inc. explained a cool new feature of Mesos that will be available in future versions: supporting the sharing of resources across task instances scheduled on a single agent node. At the moment, a persistent volume, once offered to the framework, can be scheduled to a task, but cannot be used by another task until the former has finished. This new feature will add support to enable shareability for persistent volumes. See the following jira ticket for further details MESOS-3421
Building highly available Mesos frameworks
The first day’s last talk was a very interesting one. Neil Conway from Mesosphere talked about Building highly available Mesos frameworks. His talk offered practical information to understand how Mesos deals with failure and the tools it provides to enable fault tolerant frameworks. Throughout his slides he talked about three types of failures: network, process and system failures and how mesos and the frameworks developers should work to deal with them. There is also a pretty good Mesos documentation on this same topic: Designing highly available Mesos frameworks

To conclude his talk, Neil talked about some changes that will be included in Mesos 1.1: operators/scripts will be able to tell Mesos that a partitioned agent is permanently gone, frameworks will be able to learn when a partitioned task is gone “forever” and a fine-grained task states, replacing TASK_LOST (TASK_UNREACHABLE, TASK_DROPPED, TASK_GONE & TASK_GONE_BY_OPERATOR).
Work hard, play hard
After attending a day of interesting and insightful talks, we were able to enjoy a stroll along the famous Amsterdam canals.
Kris Buytaert’s opening keynote
We arrived bright and early for the second day of the event. Kris Buytaert, CTO of Inuits delivered his keynote on the impact of distributed computing on the evolution of Devops a movement that started with the devopsday held in Gent in November 2009. Buytaert explained how the distributed platforms have deeply impacted the way we deliver software.
Ambrose: automatic metric collection and correlation in DC/OS
We then decided to listen to Mesosphere’s Nick Parker talking about “Ambrose: automatic metric collection and correlation in DC/OS”. Parker highlighted the importance of using metrics on a daily basis and how they may help foresee problems. He then explained the architecture of Ambrose, a suite of components for collecting and tagging metrics in the DC/OS system:
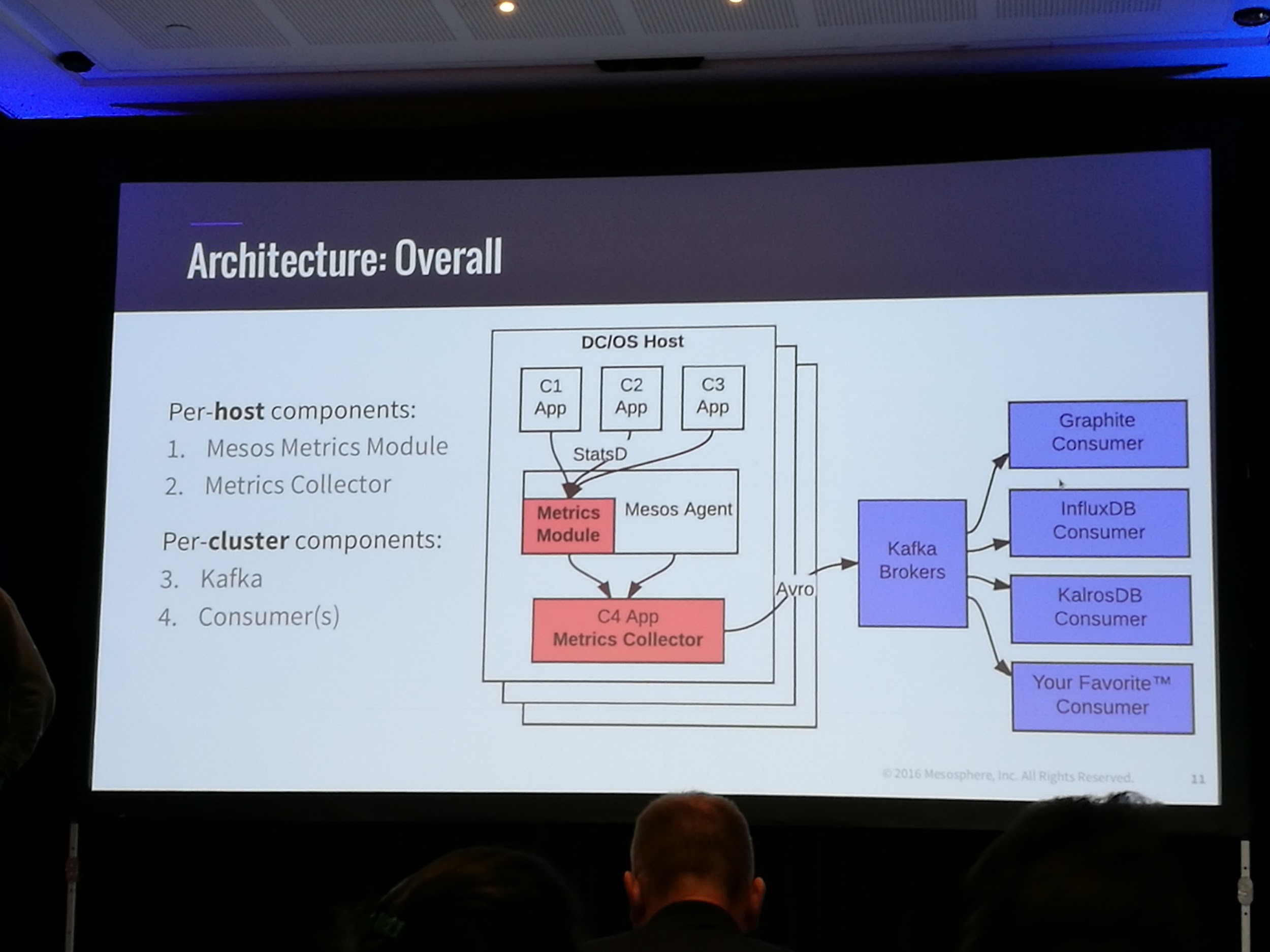
The points to be highlighted are that metrics are automatically retrieved from the containers, custom applications might publish their metrics using the StatsD endpoint, so far they are flushing the metrics to a kafka cluster (more outputs to come in the future), they are using Apache Avro for serialization and Grafana for visualization.
Jan Schlicht’s talk on “Docker at Scale” closed our MesosCon Europe experience off nicely.
Schlicht focused on why everybody is talking about containers and how they make the lives of devs and ops easier. He then explained the differences between docker and mesos containerizer and things that may go wrong when running containers at scale.
These include: hanging docker daemons, performance drawbacks because of having too many docker layers and exhausting the agent inodes.
We most definitely had an intense and exciting time at MesosCon Europe. The two-day speech-packed event confirmed that the Mesos ecosystem is packing a punch.
***
This post is co-authored by Alberto Rodriguez @ardlema and Andrés Macarrilla @amacarrilla, developers at Stratio.


