
Have you ever wondered how generative AI tools seem to work so well with images? The clever ways maintenance crews can detect pot holes on the road just by flying a drone over them or doctors being able to detect skin cancer from photos? This is possible because of the Transformers -not ‘robots in disguise’, but a neural network architecture that implements attention mechanisms. It has been a revolution in Natural Language Processing (NLP) and image/text generation tasks and allowed a great advance in other tasks related with image recognition: image classification, object detection, and semantic image segmentation. All these advances are possible with the use of Vision Transformers or ViT.
In this article we will explore what are the Vision Transformers? How do they work? And how they improve the image recognition tasks versus the Convolutional Neural Networks (CNNs).

What are the Vision Transformers?
The Vision Transformer (ViT) model architecture was introduced in a research paper published titled An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale. It was developed and published by Neil Houlsby, Alexey Dosovitskiy, and a team of authors from the Google Research Brain Team. The fine-tuning code and pre-trained models are available on this GitHub.
A transformer is a deep learning model that uses attention mechanisms to detect the weight (importance) of each part of an input data sequence (usually text). The visual transformer is a special type of transformer, which can do the same thing but with images.
How do the Vision Transformers work?
Unlike CCNs, which process images by detecting features through convolutional filters, ViTs transform the images in a series of small segments or “patches” of a certain size. For example, if you have an image of 224×224 pixels, it would be divided into 16×16 patches, making 224/16 x 224/16 = 14 x 14 = 196 patches.
Each of these patches is then flattened and transformed into a one-dimensional sequence of tokens. each token encodes a part of the image. However, because tokens are obtained after flattening the original image, information about the visual hierarchy of the image is lost, that is, which portion of the image comes before or after another part. Therefore, information about the order in which they were presented in the image is added to these vectors, it is called the positional embedding. This final sequence is the input of a transformer encoder.
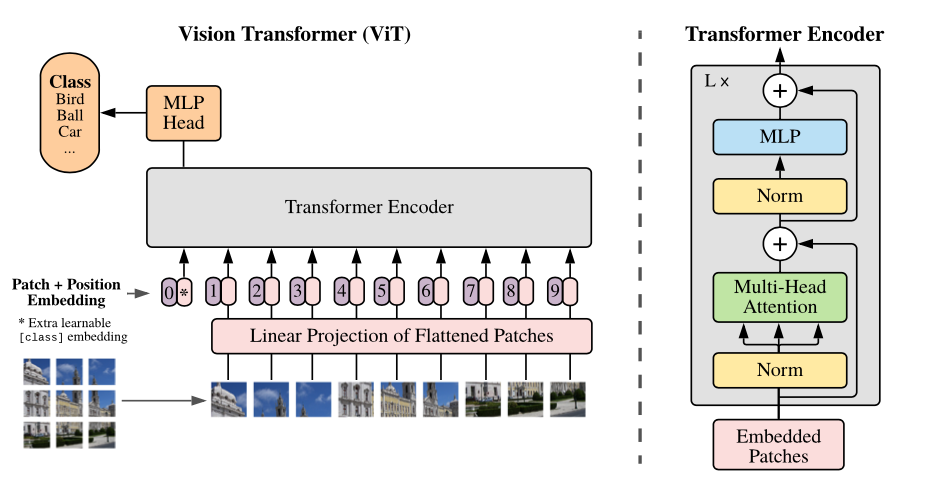
In this encoder, the self-attention mechanisms analyze each patch of the image, taking into account its relationship with the rest of the parts of the image. These compute a weighted sum of the input data, where the weights are computed based on the similarity between the input features. So, the model has the capability to evaluate the relative importance of each patch in relation to the others, allowing ViTs to capture long-range relationships between different parts of the image and to attend to different regions of the input data, based on their relevance to the task at hand.
The final output of the ViT architecture is a class prediction, obtained by passing the output of the last transformer block through a classification head, which typically consists of a single fully connected layer.
Visual Transformers vs Convolutional Neural Networks
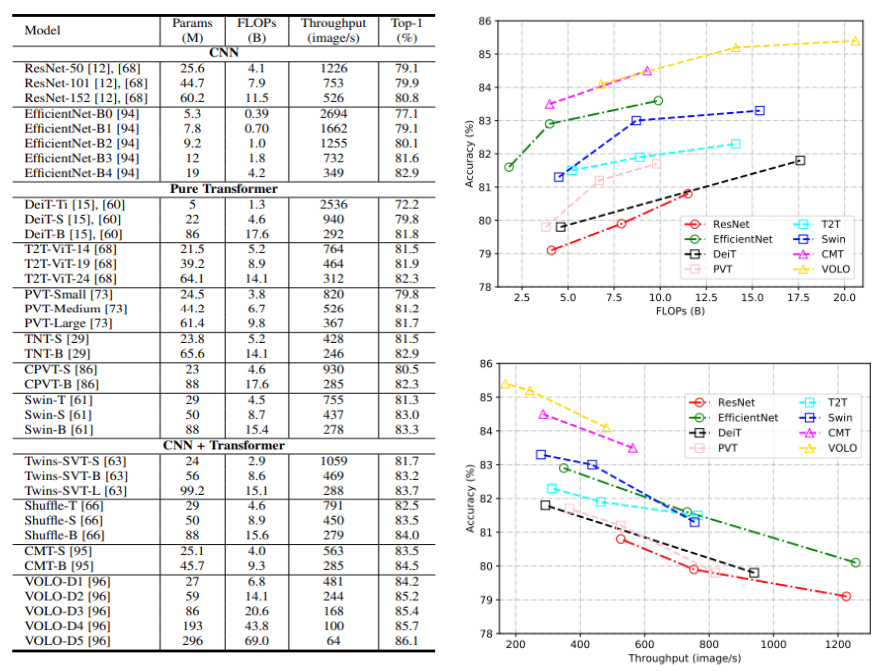
According to results obtained in this article A Survey on Visual Transformer, the Visual Transformers or the combination of ViTs with CNN allows for better accuracy compared to CNN networks. Also It has been shown that this new architecture, even with hyperparameters fine-tuning (a high intensity process of search for the best parameters for model training), can be lighter than the CNN, consuming fewer computational resources and taking less training time.
Summary
1. ViT architecture is more robust than CNN networks for images that have noise or are augmented.
2. ViT architecture performs better than CNN due to the self-attention mechanisms, which make the overall image information to be accessible from the highest to the lowest layers.
3. ViTs have the advantage of learning information better with fewer images. This is because the images are divided into small patches, so there is a greater diversity of relationships between them.
4. CNNs can generalize better with smaller datasets and get better accuracy than ViTs.
Visual Transformers in Stratio Platform
All these results and advances obtained make visual transformers the most appropriate elements to do tasks related to image recognition in generative AI tools, such as: Image Detection and Classification, Video Deepfake Detection and Anomaly Detection, Autonomous Driving and Image segmentation and cluster analysis.
Stratio Generative AI Data Fabric product not only serves to govern, process and analyze data but it is also used to develop and implement the deeplearning models on which Vision Transformers are based. Besides, it has its own module for the development and productivity of GenAI models with efficiency and agility.
Request a demo now!
About the author:

Data Science Lead in Stratio BD. Currently working on design and development of Artificial Intelligence projects, in Big Data environments and Agile teams.
Bioinformatician and Master in Big Data & Analytics with more 21 years in data sector and more than 30 AI models developed, including classic machine learning and deep learning models, reinforcement learning models and generative AI models
Amateur in languages, in addition to Spanish he speaks English and Russian, the history, photography and the oriental disciplines such as Taoism and Tai Chi.


